
单链表的基本概念
- 结点(Node):
- 结点是单链表中用于存储数据的基本单元。每个结点通常包含两个部分:数据域和指针域。数据域用于存储数据,而指针域则用于存储指向下一个结点的指针。
- 头结点(Head Node):
- 头结点是一种特殊的结点,也称为虚拟结点或哨兵结点。它通常不存储数据,或者可以存储链表的元数据,如链表长度。
- 在带有头结点的链表中,头结点是链表的第一个结点,它的存在可以简化链表操作的逻辑。
- 尾结点(Tail Node):
- 尾结点是链表中的最后一个结点。它仍然包含数据域,但指针域指向
NULL,表示链表的结束。
- 尾结点是链表中的最后一个结点。它仍然包含数据域,但指针域指向
- 头指针(Head Pointer):
- 头指针是指向单链表第一个结点的指针。它是链表操作的起点,对于单链表来说至关重要。
- 如果链表的头指针是
NULL,则表示链表为空。如果链表带有头结点,头指针指向头结点;否则,它指向第一个带有数据的结点。
- 尾指针(Tail Pointer):
- 尾指针是指向单链表最后一个结点(尾结点)的指针。虽然尾指针不是必需的,但它的存在可以使得链表尾部的操作更加方便和高效。
- 构建单链表的方法:
- 头插法(Head Insertion):在链表的头部插入一个结点,使得新结点成为新的头结点。这需要更新头指针。
- 尾插法(Tail Insertion):在链表的尾部插入一个结点,使得新结点成为新的尾结点。这需要更新尾指针(如果存在)。
常见的链表主要可以分为以下几种类型:
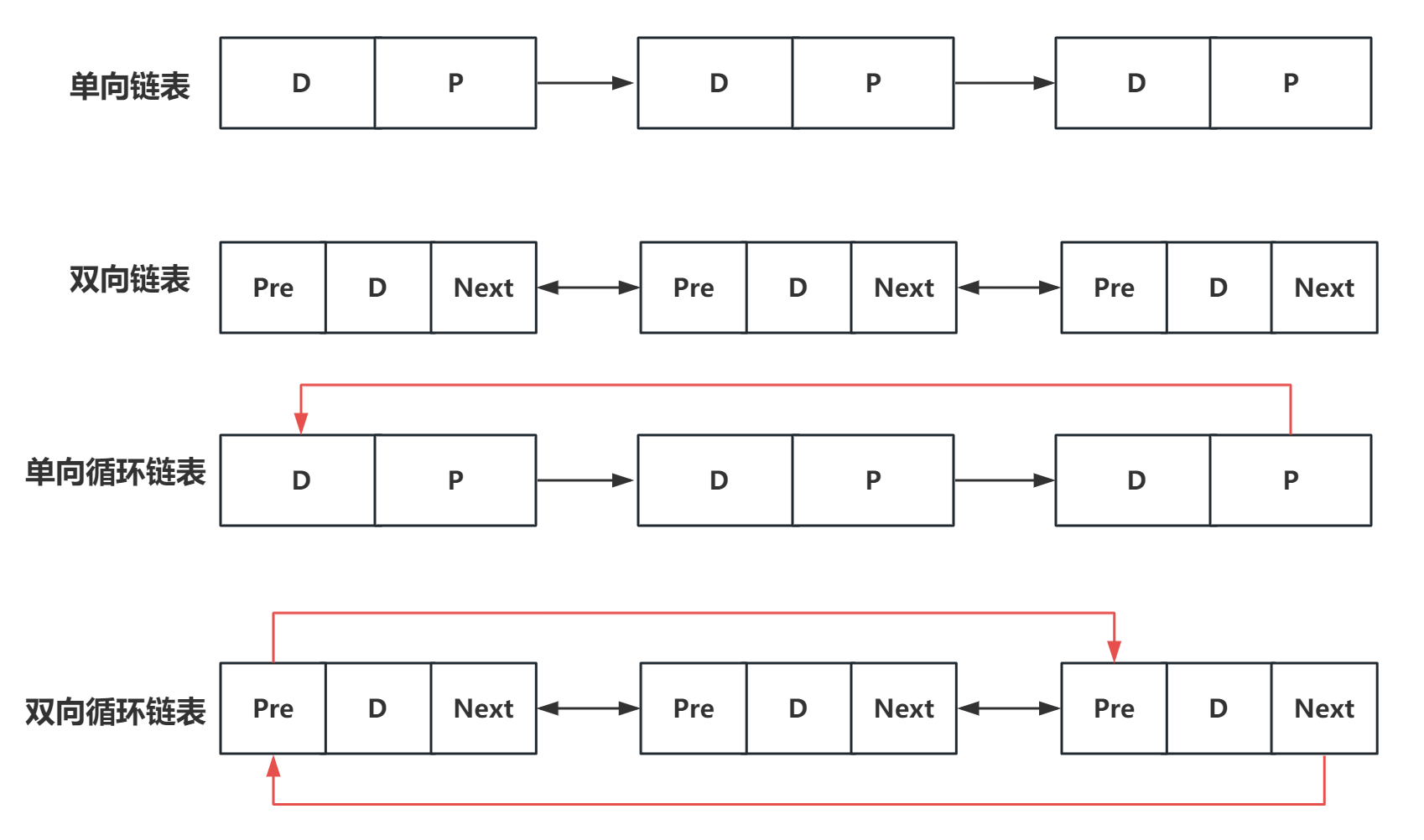
单链表的基本/核心操作
- 创建单链表:创建单链表通常从创建头结点开始,然后根据需要添加数据结点。
- 销毁单链表:销毁单链表需要释放链表中所有结点的内存。这通常通过遍历链表并逐个释放结点来完成。
- 插入新结点:插入操作可以在链表的头部或尾部进行: a. 头插法:在链表头部插入新结点,新结点成为链表的第一个结点。 b. 尾插法:在链表尾部插入新结点,新结点成为链表的最后一个结点。
- 根据索引插入结点:在链表的指定位置插入新结点,需要先遍历链表找到插入点,然后调整指针。
- 删除结点:删除操作可以基于元素的值或索引:
- 根据元素值删除:遍历链表,找到具有特定值的结点,并从链表中移除。
- 根据索引删除:遍历链表,找到特定索引的结点,并从链表中移除。
- 查询结点:查询操作可以基于数据域的值或索引:
- 根据值查询:遍历链表,查找具有特定值的第一个结点。
- 根据索引查询:遍历链表,查找特定索引的结点。
- 遍历单链表:遍历单链表是最基本的操作之一,通常用于访问链表中的每个结点,进行打印或其他处理。
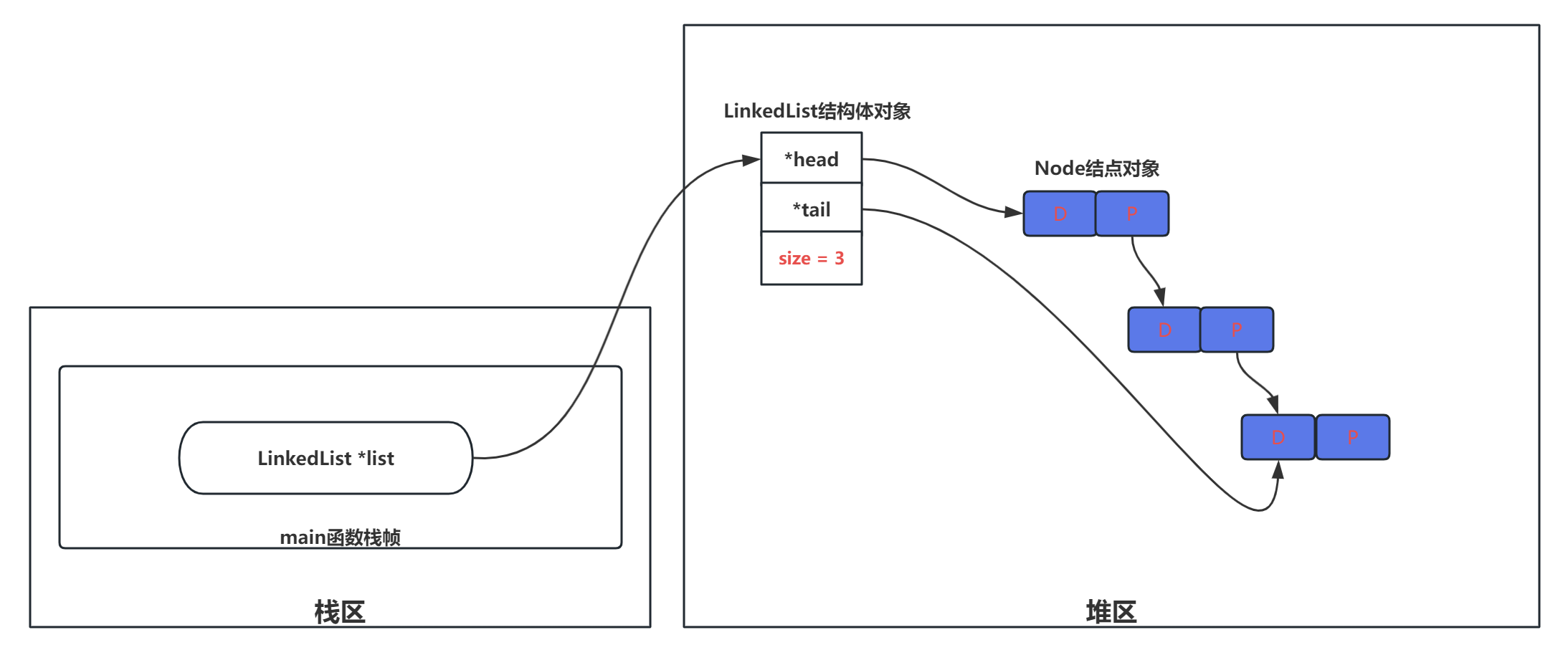
单链表的创建和销毁
创建单链表
LinkedList *create_linked_list() {
return calloc(1, sizeof(LinkedList));
}
销毁单链表
- 释放链表结点:从链表的头部开始,逐个结点释放内存。在释放当前结点之前,需要先保存下一个结点的地址。
- 释放链表结构:在所有结点都被释放之后,释放整个链表结构的内存。
遍历链表的标准做法:
遍历单链表是许多链表操作的基础,以下是一般的步骤:
- 初始化当前结点:创建一个指针
current,通常指向链表的头结点list->head。 - 使用 while 循环:使用
while循环来遍历链表,条件通常是(current != NULL)。 - 处理逻辑:在循环体内部,执行需要的操作,例如打印结点数据或销毁结点。
- 移动到下一个结点:在循环的每次迭代结束时,更新
current指针以指向下一个结点,通常使用current = current->next;。 - 循环结束条件:循环继续进行,直到
current为NULL,表示已经到达链表的末尾。
void destroy_linked_list(LinkedList *list) {
Node *curr = list->head;
while (curr != NULL) {
Node *next = curr->next; // 保存下一个结点
free(curr); // 释放当前结点
curr = next; // 移动到下一个结点
}
// 链表的所有结点都已释放,现在可以释放链表结构本身
free(list);
}
打印链表
- 初始化当前结点:使用一个指针
curr初始化为链表的头结点list->head。 - 遍历链表:使用
while循环遍历链表,直到curr为NULL。 - 打印当前结点数据:在循环内部,打印当前结点
curr的数据域curr->data。 - 添加箭头指示:如果当前结点不是链表的最后一个结点(即
curr->next不为NULL),则打印一个箭头->作为分隔。 - 移动到下一个结点:在循环的每次迭代结束时,将
curr更新为下一个结点curr->next。 - 完成打印:在所有结点都被打印后,打印一个换行符
\n。
void print_list(LinkedList *list) {
Node *curr = list->head;
while (curr != NULL) {
printf("%d ->", curr->data);
curr = curr->next;
}
printf("NULL\n");
}
插入节点
头插法插入结点
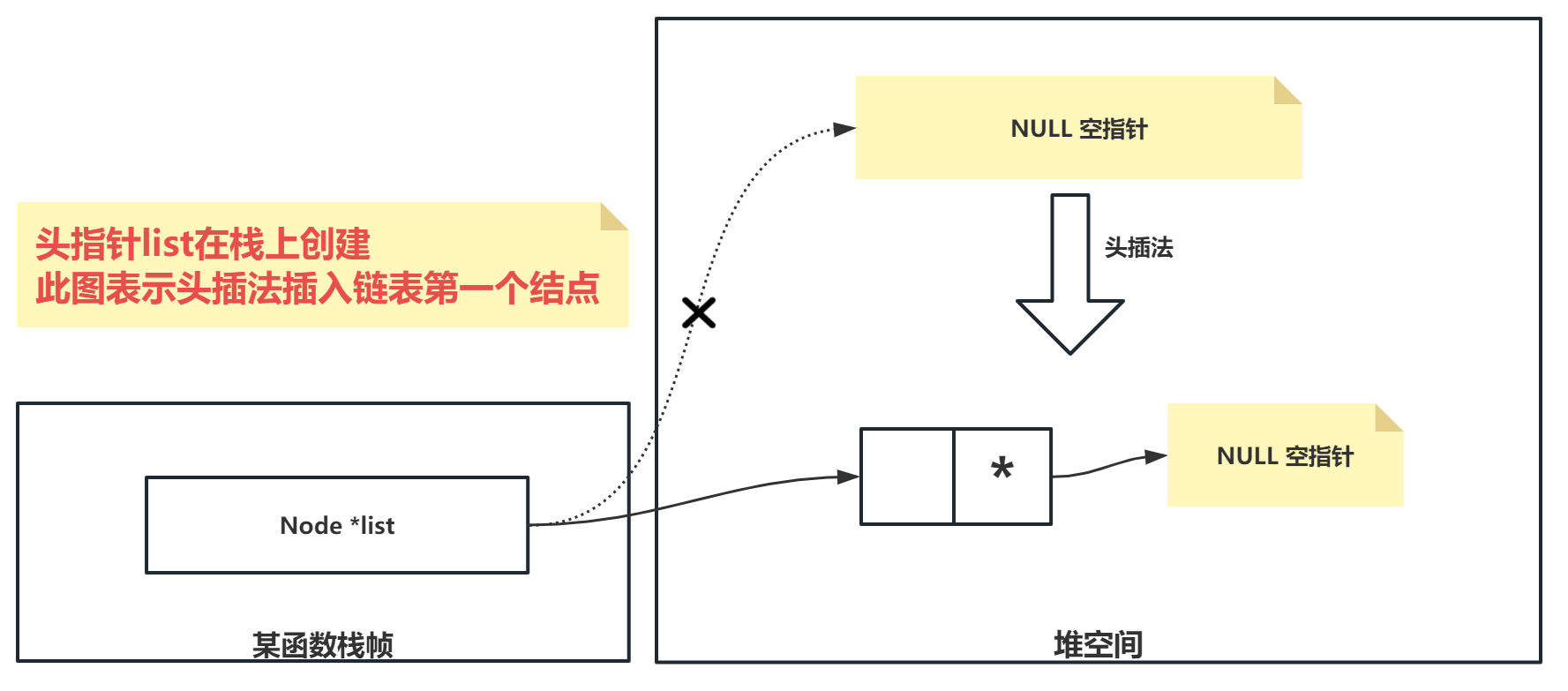
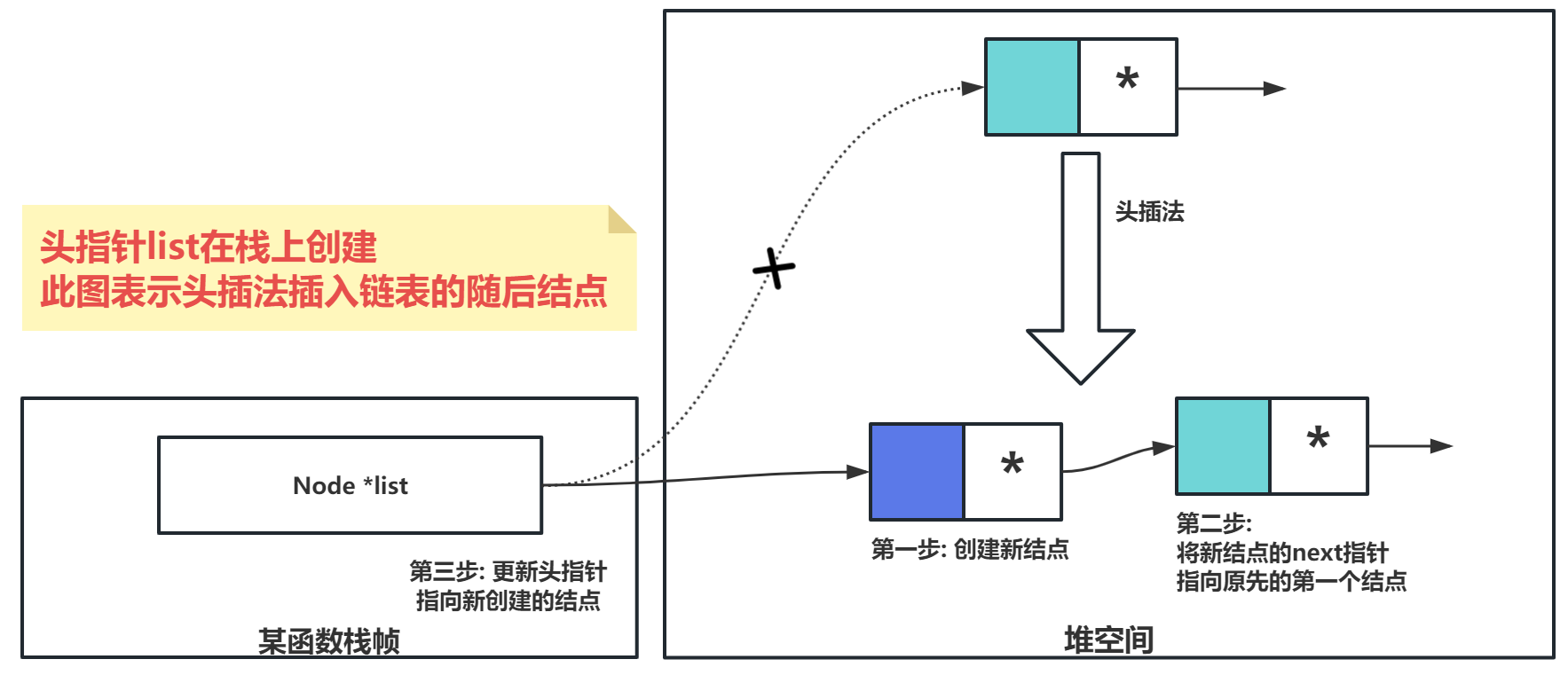
- 创建新结点:分配内存给新结点。
- 初始化新结点:
- 给新结点的数据域赋值。
- 将新结点的指针域指向原本的第一个结点。
- 更新链表结构信息:
- 头指针指向新结点,使其成为链表的第一个结点。
- 如果尾结点指针为
NULL(意味着以前的链表是空的),则更新尾结点指针指向新结点。 - 链表长度增加 1。
bool add_before_head(LinkedList *list, DataType new_data) {
Node *new_node = malloc(sizeof(Node));
if (new_node == NULL) {
printf("错误:malloc 在 add_before_head 中失败。\n");
return false;
}
new_node->data = new_data;
new_node->next = list->head; // 新结点指向原本的第一个结点
list->head = new_node; // 新结点成为第一个结点
if (list->tail == NULL) {
list->tail = new_node; // 如果链表为空,更新尾结点指针
}
list->size++;
return true;
}
尾插法插入结点
- 创建新结点:分配内存给新结点。
- 初始化新结点:
- 给新结点的数据域赋值。
- 将新结点的指针域指向
NULL,因为新结点要成为新的尾结点。
- 更新链表结构信息:
- 如果以前的链表为空(尾结点指针为
NULL),则头指针也应该指向新结点。 - 如果以前的链表非空,则头指针不用更新。只需要将以前的尾结点指针指向的新结点,指向新创建的结点(即更新前一个尾结点的
next指针)。需要注意的是,这步需要保证单链表非空才能够执行否则链表没有结点,只有NULL,将导致空指针操作的问题。 - 将链表的尾结点指针指向新结点。
- 链表长度增加 1。
- 如果以前的链表为空(尾结点指针为
bool add_behind_tail(LinkedList *list, DataType new_data) {
// 分配新结点, 并初始化数据域和指针域
Node *new_node = malloc(sizeof(Node));
if (new_node == NULL) {
printf("错误:malloc 在 add_behind_tail 中失败");
return false;
}
new_node->data = new_data;
new_node->next = NULL;
if (list->tail == NULL) {
// 链表为空
list->head = new_node;
list->tail = new_node; // 旧尾结点指向新结点
} else {
// 链表非空,将新结点链接到当前尾结点
list->tail->next = new_node;
}
list->tail = new_node; // 更新尾结点指针
list->size++;
return true;
}
根据索引插入结点
- 参数校验:确保提供的索引
idx在合法范围内,即[0, 链表长度]。 - 边界值处理:
- 如果索引为
0,则执行头插法。 - 如果索引等于链表长度,则执行尾插法。
- 如果索引为
- 中间插入结点:
- 创建一个新结点,并将其数据部分设置为要插入的数据。
- 使用一个
current结点指针遍历链表,找到目标索引的前一个结点。 - 将新结点的指针指向
current结点的下一个结点。 - 将
current结点的指针指向新结点。 - 更新链表长度。
bool add_by_idx(LinkedList *list, int idx, DataType new_data) {
if (idx < 0 || idx > list->size) {
printf("错误:非法的传参 idx:%d!\n", idx);
return false;
}
if (idx == 0) {
return add_before_head(list, new_data);
}
if (idx == list->size) {
return add_behind_tail(list, new_data);
}
Node *new_node = malloc(sizeof(Node));
if (new_node == NULL) {
printf("错误:malloc 在 add_by_idx 中失败!\n");
return false;
}
new_node->data = new_data;
Node *prev = list->head;
for (int i = 0; i < idx - 1; ++i) {
prev = prev->next;
} // for 循环结束时, prev 指针指向 idx - 1 位置的结点
new_node->next = prev->next;
prev->next = new_node;
list->size++;
return true;
}
查找与删除结点
根据索引查找结点
- 参数校验:确保提供的索引
idx在合法范围内,即[0, 链表长度 - 1]。 - 遍历链表:使用一个指针
current从链表的头结点开始遍历链表。 - 查找目标索引的结点:在遍历过程中,通过索引计数来查找目标索引的结点。当索引计数等于提供的索引
idx时,停止遍历。 - 返回结点:如果找到了目标索引的结点,则返回该结点的指针。如果没有找到(索引超出范围),则返回
NULL。
Node *search_by_data(LinkedList *list, DataType data) {
Node *curr = list->head;
while (curr != NULL) {
if (data == curr->data) {
return curr;
}
curr = curr->next;
}
return NULL;
}
根据索引删除结点
- 参数校验:确保链表不为空,并且提供的索引
idx在合法范围内,即[0, 链表长度 - 1]。 - 删除第一个结点:如果索引为
0,则删除头结点。更新头指针指向下一个结点,并处理尾指针。 - 删除非第一个结点:如果索引不为
0,则需要遍历链表找到待删除结点的前一个结点。 - 更新指针:将前一个结点的
next指针指向待删除结点的下一个结点,从而绕过待删除结点。 - 更新尾指针:如果删除的是尾结点,需要更新尾指针指向新的最后一个结点。
- 释放内存:释放待删除结点的内存。
- 更新链表长度。
bool delete_by_idx(LinkedList *list, int idx) {
if (idx < 0 || idx > list->size) {
printf("错误:非法的传参 idx:%d!\n", idx);
return false;
}
Node *curr = list->head;
Node *prev = NULL;
if (idx == 0) {
list->head = curr->next;
if (list->size == 1) {
list->tail = NULL;
}
free(curr);
list->size--;
return true;
}
curr = curr->next;
for (int i = 0; i < idx - 1; ++i) {
prev = curr;
curr = curr->next;
}
prev->next = curr->next;
if (idx == list->size - 1) {
list->tail = NULL;
}
free(curr);
list->size--;
return true;
}
根据数据删除一个结点
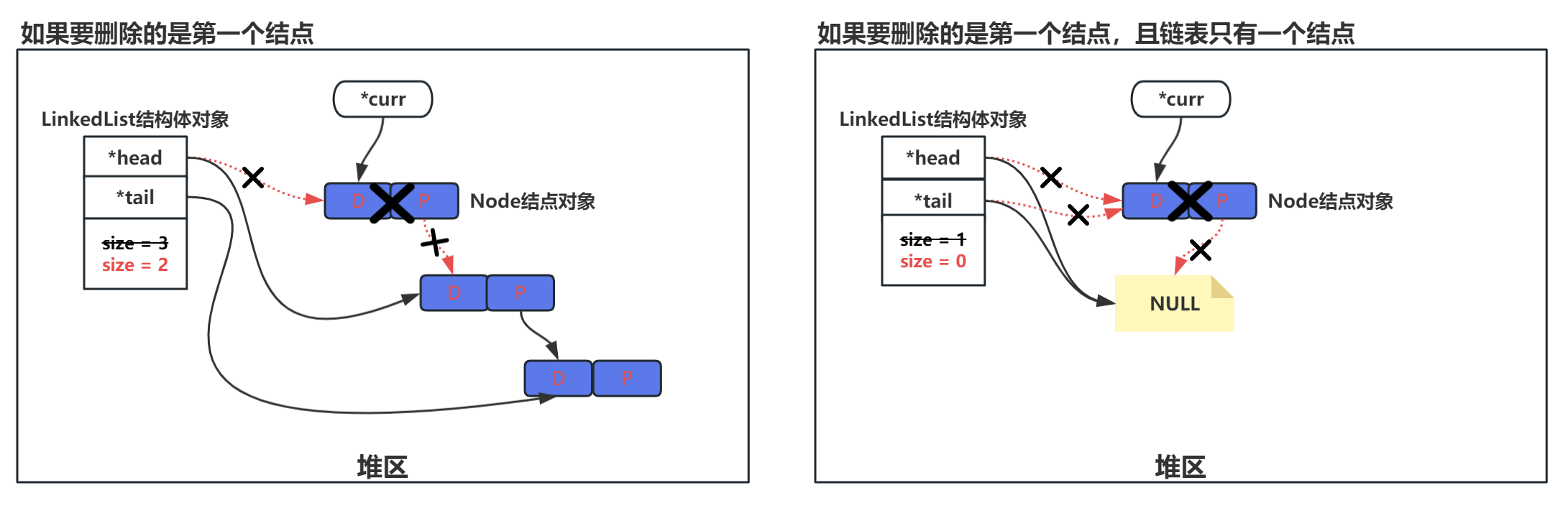

- 处理头结点情况:如果头结点包含要删除的数据,更新头指针指向下一个结点,并释放原头结点的内存。
- 处理非头结点情况:使用两个指针
prev和curr遍历链表,prev指向当前结点的前一个结点,curr指向当前结点。 - 查找并删除结点:在遍历过程中,找到包含要删除数据的结点,更新
prev结点的next指针指向curr结点的下一个结点。 - 更新尾指针:如果删除的是尾结点,更新尾指针指向
prev结点。 - 释放内存:释放被删除结点的内存。
- 更新链表长度。
bool delete_by_data(LinkedList *list, DataType data) {
Node *curr = list->head;
Node *prev = NULL;
// 如果要删除的结点是第一个结点
if (curr->data == data) {
list->head = curr->next;
if (list->head == NULL) {
list->tail = NULL;
}
free(curr);
} else {
// 从第二个结点开始遍历查找待删除目标结点
while (curr != NULL && curr->data != data) {
prev = curr;
curr = curr->next;
}
// 如果找到了目标结点
if (curr != NULL) {
prev->next = curr->next;
if (prev->next == NULL) {
list->tail = prev;
}
free(curr);
} else {
// 未找到目标结点
return false;
}
}
list->size--;
return true;
}
相关题目:203. 移除链表元素
单链表总结
- 头部操作的时间复杂度:由于头部操作通常只涉及更新头指针,因此大多数头部操作(如头插、删除头部结点、访问头部结点)具有 O(1) 的时间复杂度。
- 尾部操作的时间复杂度:尾指针的存在使得在链表尾部新增结点(尾插)的操作也具有 O(1) 的时间复杂度。
- 结点操作的限制:单链表只能在一个确定的结点后面执行操作,如新增、删除、访问,因为单链表的每个结点只有一个指向后继结点的指针。
- 前驱结点的操作:任何在结点前面的操作都需要先遍历链表找到前驱结点,然后在结点的后面执行操作,此时时间复杂度为 O(n)。
- 双向链表的优势:双向链表在每个结点上增加了一个指向前驱结点的指针,这使得在任意结点附近(前后)都可以直接进行 O(1) 时间复杂度的操作。
结论:
- 单链表在头部和尾部操作具有时间复杂度的优势,但在中间结点的操作受到限制。
- 双向链表提供了更高的灵活性和效率,特别是在需要频繁访问和修改链表中间结点的场景中,因此它是更普遍的选择。
快慢指针
快慢指针法的基本原理:
- 初始化指针:同时初始化两个指针
slow和fast,它们都指向链表的头部。 - 遍历链表:在链表中进行遍历,每次遍历时,将
fast指针向前移动两步,而slow指针只向前移动一步。 - 结束条件:当
fast指针到达链表末尾或其下一个节点为NULL时,遍历结束。 - 中间节点:在遍历结束时,
slow指针将指向链表的中间节点。

相关题目:141. 环形链表
bool hasCycle(struct ListNode *head) {
struct ListNode *fast = head;
struct ListNode *slow = head;
while (fast && fast->next) {
slow = slow->next;
fast = fast->next->next;
if(slow == fast) {
return true;
}
}
return false;
}
单链表的反转
循环解法
- 初始化指针:
- 需要三个指针:
curr、prev和next。 curr用于遍历链表,初始时指向链表的第一个结点。prev用于指向curr的前驱结点,初始时指向NULL。next用于临时存储curr的后继结点。
- 需要三个指针:
- 遍历链表:
- 从链表的头结点开始,使用
curr指针遍历链表。 - 当
curr指向NULL时,遍历结束,反转完成。
- 从链表的头结点开始,使用
- 反转指针:
- 在遍历的过程中,首先使用
next指针存储curr的后继结点(curr->next)。 - 然后,将
curr结点的next指针指向prev,完成当前结点的反转。
- 在遍历的过程中,首先使用
- 更新指针:在每次遍历后,更新
prev为curr,然后将curr移动到next指向的位置。 - 循环结束:当
curr指向NULL时,prev将指向原本的尾结点,即反转后链表的第一个结点。
struct ListNode* reverseList(struct ListNode* head) {
struct ListNode* curr = head;
struct ListNode* prev = NULL;
while(curr) {
struct ListNode* succ = curr->next;
curr->next = prev;
prev = curr;
curr = succ;
}
return prev;
}
递归解法
- 递归体:递归体是递归函数中自我调用的部分,它负责将问题分解为更小的子问题。
- 分解思路:对于一个有 n 个结点的单链表,我们可以将其分解为:反转第一个结点和剩余的 n-1 个结点的单链表。
- 递归出口:当链表为空(
head == NULL)或只有一个结点(head->next == NULL)时,递归结束。 - 递归逻辑:
- 在递归中,首先处理第一个结点的反转,即将其
next指针指向之前已经反转的部分。 - 然后,递归调用处理剩余链表的反转。
- 首先,递归调用反转函数,以处理链表剩余的 n-1 个结点。这一步是递归的主体,它将问题分解为更小的子问题。
- 在递归调用返回后,处理反转后的 n-1 个结点中的尾结点,使其指向原本的第一个结点(head)。这一步是递归过程中的关键操作,它将反转后的子链表与原链表连接起来。
- 最后,更新 head 指针指向递归调用返回的新头指针。这一步是递归出口的一部分,它确保了整个链表的反转。
- 在递归中,首先处理第一个结点的反转,即将其


struct ListNode* reverse(struct ListNode* pre, struct ListNode* cur) {
if(!cur)
return pre;
struct ListNode* temp = cur->next;
cur->next = pre;
return reverse(cur, temp);
}
struct ListNode* reverseList(struct ListNode* head){
return reverse(NULL, head);
}