
二叉搜索树的定义
二叉树的定义: 二叉树是一种分层的数据结构,其中每个节点最多有两个子节点。这种结构允许每个节点有两个分支,分别指向其左子树和右子树。
二叉树的特殊形态:
- 完全二叉树(Complete Binary Tree):如果二叉树的高度为 h,除了第 h 层之外,所有层的节点数都达到最大,且第 h 层的节点从左到右连续排列,这样的树被称为完全二叉树。
- 满二叉树(Full Binary Tree):如果二叉树的每一层的节点数都达到最大,包括最底层,这样的树被称为满二叉树。
二叉搜索树(Binary Search Tree, BST): 二叉搜索树是一种特殊的二叉树,具有以下性质:
- 每个节点的左子树只包含小于该节点值的节点。
- 每个节点的右子树只包含大于该节点值的节点。
概念区分:
- 二叉搜索树的定义侧重于节点值的大小关系。
- 满二叉树和完全二叉树的定义侧重于二叉树的结构和形态。
二叉搜索树的实现

#ifndef BST_H
#define BST_H
#include<stdbool.h>
typedef int KeyType;
typedef struct node {
KeyType key; ///< 结点 key 值, 具有唯一性
struct node *left; ///< 左子树
struct node *right; ///< 右子树
} TreeNode;
// 推荐定义一个二叉搜索树的结构体, 这样更便于扩展
typedef struct {
TreeNode *root; ///< 根结点指针
} BST;
/**
* @brief 创建一棵空的 BST
* @return BST
*/
BST *bst_create();
/**
* @brief 销毁一棵 BST
* @param tree BST
*/
void bst_destroy(BST *tree);
/**
* @brief 根据 Key 插入一个新结点
* @param tree BST
* @param key 键值
* @return bool
*/
bool bst_insert(BST *tree, KeyType key);
/**
* @brief 根据 Key 搜索某个结点并返回
* @param tree BST
* @param key 键值
* @return BST 结点指针
*/
TreeNode *bst_search(BST *tree, KeyType key);
/**
* @brief 根据 Key 删除一个结点
* @param tree BST
* @param key 键值
* @return bool
*/
bool bst_delete(BST *tree, KeyType key);
/**
* @brief DFS 先序遍历
* @param tree BST
*/
void bst_preorder(BST *tree);
/**
* @brief DFS 中序遍历
* @param tree BST
*/
void bst_inorder(BST *tree);
/**
* @brief DFS 后序遍历
* @param tree BST
*/
void bst_postorder(BST *tree);
/**
* @brief BFS 层次遍历
* @param tree BST
*/
void bst_levelorder(BST *tree);
#endif // !BST_H
二叉搜索树的创建
BST *bst_create()
{
return calloc(1, sizeof(BST));
}
二叉搜索树的插入操作
- 初始化指针:设置两个指针,一个用于寻找插入位置(通常称为
current或node),另一个用于指向插入位置的父节点(称为parent)。 - 遍历 BST:从根节点开始,沿着树进行深度优先搜索,以确定新节点的插入位置。搜索路径类似于一条带有判断条件的单链表。
- 确定插入位置:在遍历过程中,如果新节点的键值小于当前节点的键值,则移至左子树;如果新节点的键值大于当前节点的键值,则移至右子树。这一过程一直持续到找到一个空位(即
NULL指针)。 - 处理键值重复:如果在遍历过程中发现新节点的键值与现有节点的键值相同,则插入操作失败。
- 执行插入:一旦找到插入位置,
parent指针将指向新节点的父节点,而NULL指针的位置将被新节点所取代。在 BST 中,插入操作不是通过parent->next = newnode这样的链表操作,而是根据新节点的键值与父节点键值的比较结果,决定将新节点链接到parent的左子树或右子树。 - 特殊情况处理:如果 BST 在插入操作前是空的,即根节点指针为
NULL,则新节点将成为根节点,需要更新根节点指针以指向新节点。
bool bst_insert(BST *tree, KeyType key) {
// 初始化两个指针 parent 和 curr
TreeNode *curr = tree->root;
TreeNode *parent = NULL;
// 遍历这课 BST 树, 根据 key 值的大小关系, 决定向左向右
while (curr != NULL) {
int diff = key - curr->key;
if (diff > 0) {
// 待插入结点的 key 值比当前结点 key 值大, 向右走
parent = curr;
curr = curr->right;
} else if (diff < 0) {
// 待插入结点的 key 值比当前结点 key 值小, 向左走
parent = curr;
curr = curr->left;
} else {
// 待插入结点的 key 值和当前结点 key 值相等, 插入失败
return false;
}
}
// while 循环结束且函数并没有返回, 说明找到了插入位置
// 说明 key 值没有重复
// curr 指针就是 NULL, parent 指向插入位置的父结点
// 分配一个新结点, 初始化它, 建议使用 calloc 避免左右子树有野指针
TreeNode *new_node = calloc(1, sizeof(TreeNode));
if (new_node == NULL) {
printf("error: calloc failed in bst_insert.\n");
exit(-1);
}
new_node->key = key;
// 在执行插入左右子树判断之前, 要先判树是否为空
// 注意不能使用 curr 指针来进行判断, 因为当 curr 指向 NULL 时
// 有两种可能性:
// 1.BST 插入前是空树 2. 找到插入位置
if (parent == NULL) {
// 插入之前, BST 是空树, 只需要更新根节点指针即可
tree->root = new_node;
return true;
}
// 插入之前树非空, 那就根据 key 值大小关系决定插入左子树还是右子树
int diff = key - parent->key;
if (diff > 0) {
// 插入右子树
parent->right = new_node;
} else {
// 插入左子树
parent->left = new_node;
}
// 插入成功
return true;
}
二叉搜索树的搜索操作
- 初始化当前结点:使用一个指针
curr初始化为根结点tree->root,用于遍历树。 - 遍历树:使用
while循环遍历树,根据键值key与当前结点键值的比较结果,决定遍历的方向。 - 搜索逻辑:
- 如果
key大于当前结点的键值,移动到右子结点。 - 如果
key小于当前结点的键值,移动到左子结点。 - 如果
key等于当前结点的键值,返回当前结点,表示找到了目标结点。
- 如果
- 搜索失败:如果遍历结束且未返回,说明目标键值的结点不存在,返回
NULL。
TreeNode *bst_search(BST *tree, KeyType key) {
// 初始化 curr 指针用于遍历寻找目标结点
TreeNode *curr = tree->root;
// 遍历这课 BST 树, 根据 key 值的大小关系, 决定向左向右
while (curr != NULL) {
int diff = key - curr->key;
if (diff > 0) {
// 待插入结点的 key 值比当前结点 key 值大, 向右走
curr = curr->right;
} else if (diff < 0) {
// 待插入结点的 key 值比当前结点 key 值小, 向左走
curr = curr->left;
} else {
// 待插入结点的 key 值和当前结点 key 值相等, 找到了目标结点, 直接返回它
return curr;
}
}
// while 循环结束且函数未返回, 说明目标 key 结点不存在, 此时 curr
// 找到插入位置, curr 是一个空指针
return NULL; // 查找失败
}
二叉树的删除操作
在数据结构中,“度”(Degree)指的是一个节点拥有的子节点数量。在二叉搜索树(BST)中,节点的度有三种可能:
- 度为 0:节点没有子节点,这种节点称为“叶子节点”(Leaf Node)。
- 度为 1:节点有一个子节点,可能是左子树或右子树。
- 度为 2:节点有两个子节点,即既有左子树也有右子树。
BST 的删除操作需要特别注意,不能因为删除某个节点而导致树结构断裂,必须保持 BST 的性质。删除操作的复杂度与节点的度有关,度越高,删除操作越复杂。以下是 BST 删除节点的一般步骤:
- 初始化指针:设置两个指针,
curr用于遍历寻找目标节点,parent用于指向curr的父节点。 - 查找目标节点:从根节点开始遍历 BST,如果目标节点不存在,则删除失败。
- 执行删除操作:根据节点的度执行不同的删除操作,确保 BST 的性质不被破坏。
- 释放内存:删除操作完成后,释放相应节点的内存。
对于度为 0 或 1 的节点,删除操作相对简单,因为它们没有或只有一个子节点,可以直接将父节点的对应子树指针指向子节点的子树(如果有的话)。


对于度为 2 的节点,删除操作更复杂。一种常见的方法是找到一个“替死鬼”节点,即左子树中的最大节点或右子树中的最小节点,这个节点的度一定是 0 或 1。然后将这个“替死鬼”节点的值替换到度为 2 的节点中,再删除原来的“替死鬼”节点。这样,度为 2 的节点的删除就被“降级”为度为 0 或 1 的节点的删除。
这个过程可以通过以下步骤实现:
- 找到“替死鬼”节点:从待删除节点的右子树中找到最小值节点,或者从左子树中找到最大值节点。
- 替换值:将“替死鬼”节点的值复制到待删除节点中。
- 删除“替死鬼”节点:由于“替死鬼”节点的度为 0 或 1,可以按照相应的删除操作进行删除。
这种方法确保了 BST 的性质得以保持,并且简化了删除操作。
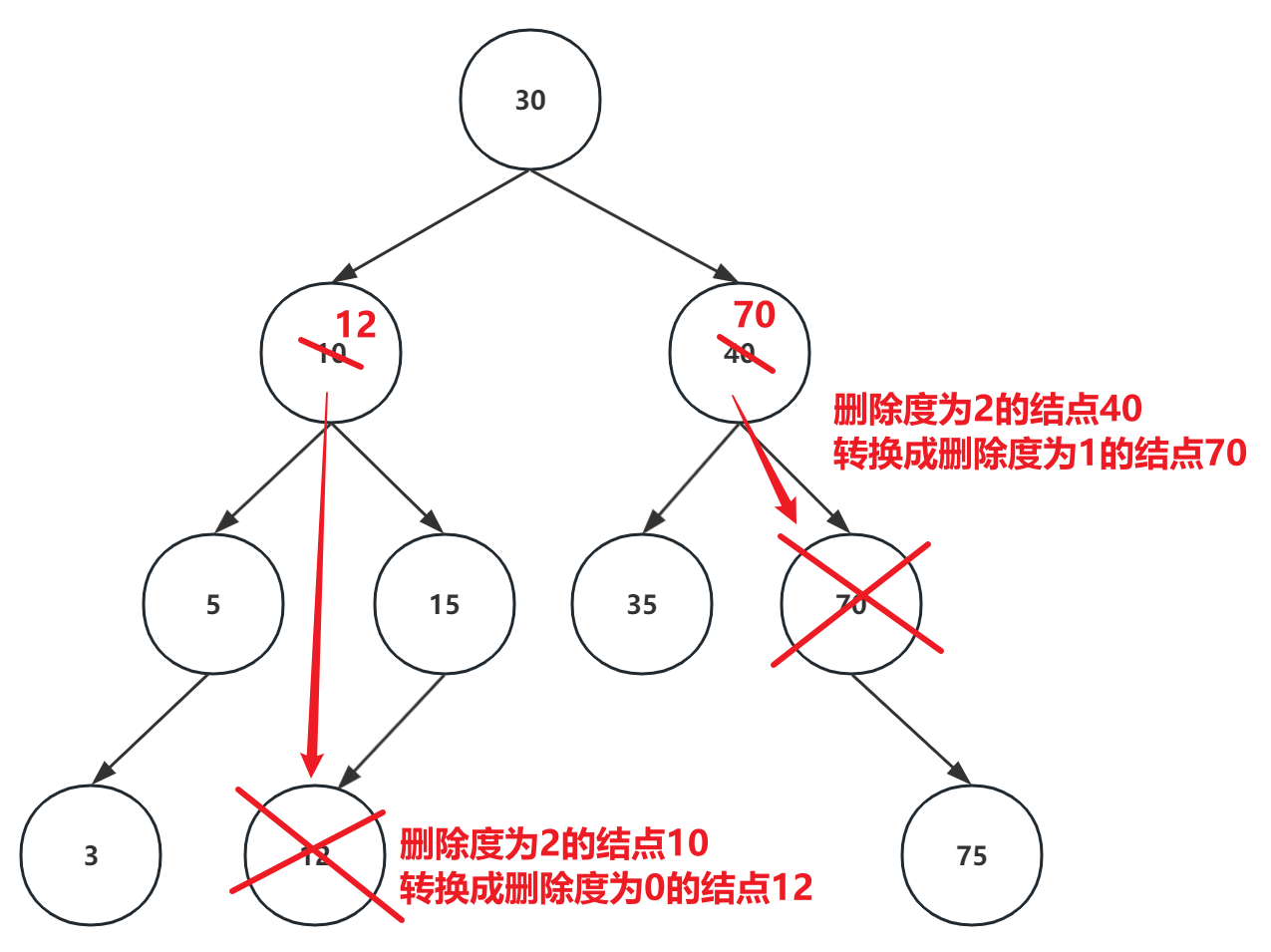
具体步骤如下:
- 查找待删除结点:使用两个指针
curr和parent分别指向当前遍历的结点和其父结点。 - 搜索逻辑:根据键值
key与当前结点键值的比较结果,决定遍历的方向。 - 处理度为 2 的结点:如果待删除结点有两个子结点,找到其右子树中的最小值结点,将其替换到待删除结点的位置,并更新
curr指向该最小值结点。 - 处理度为 0 或 1 的结点:确定待删除结点的子结点(如果有的话),并将其链接到待删除结点的父结点。
- 更新根结点:如果待删除结点是根结点,更新根结点指针。
- 释放内存:释放待删除结点的内存。
// 根据 key 删除一个结点
bool bst_delete(BST *tree, KeyType key) {
// 初始化两个指针用于查找及删除目标结点
TreeNode *curr = tree->root;
TreeNode *parent = NULL;
// 遍历 BST, 根据 key 值的大小关系, 决定向左向右
while (curr != NULL) {
int diff = key - curr->key;
if (diff > 0) {
// 待插入结点的 key 值比当前结点 key 值大, 向右走
parent = curr;
curr = curr->right;
} else if (diff < 0) {
// 待插入结点的 key 值比当前结点 key 值小, 向左走
parent = curr;
curr = curr->left;
} else {
// 待插入结点的 key 值和当前结点 key 值相等, 说明找到目标待删除结点
// 结束循环, 以开始删除操作
break;
}
}
// 若结点不存在, 直接返回 false 表示删除失败
// while 循环结束时, 程序运行是什么状态呢?
// while 循环结束有两种可能性:
// 1. 依靠 break 结束循环, 说明找到待删除结点
// curr 指针指向待删除结点, parent 指向待删除结点的父结点
// 2. 依靠 curr 指向 NULL 结束循环, 说明没有找到待删除结点
// 此时 curr 指向 NULL, 而 parent 指向插入位置的父结点
// 此时程序不应当继续执行了, 应当结束返回函数, 删除失败
if (curr == NULL) {
return false; // 删除失败
}
// 根据结点度的不同, 做不同的处理
// 这一步主要目的是让待删除结点从 BST 结构中移除, 执行一系列指针的操作
// 将度为 2 结点的删除, 降级为度为 0 或 1 结点的删除
if (curr->left != NULL && curr->right != NULL) {
// 待删除结点度为 2
TreeNode *min_node = curr->right; // 用于寻找右子树最小值结点的指针
parent = curr; // parent 需要最终指向右子树最小值结点的父结点
while (min_node->left != NULL) {
parent = min_node;
min_node = min_node->left;
} // while 循环结束时, min_node 指向右子树最小值结点, parent 指向它的父结点
curr->key = min_node->key;
curr = min_node; // curr 指向最终要指向待删除结点
}
// 代码执行到这里
// curr 指向待删除结点
// parent 指向待删除结点的父结点
// 而且 curr 指向的待删除结点, 度一定为 0 或 1
// 绝不可能是度为 2 的
// 统一处理度为 0 或 1 结点的删除
// 先确定待删除结点的父结点究竟指向待删除结点的左子树还是右子树
TreeNode *child = (curr->left != NULL) ? (curr->left) : (curr->right);
// 考虑一种特殊情况:
// 假如删除的结点是根结点, 此时需要更新根结点指针
// 但是要注意, 此时的根节点一定是度为 1 或 0 的
if (parent == NULL) {
// 删除的结点是根结点
tree->root = child;
} else {
// 删除的结点不是根结点
if (parent->left == curr) {
// 待删除结点是父结点的左子树, 于是让父结点的左子树指向 child
parent->left = child;
} else {
// 待删除结点是父结点的右子树, 于是让父结点的右子树指向 child
parent->right = child;
}
}
// free 结点, 删除成功, 返回 true
free(curr);
return true;
}
二叉树的遍历操作
深度优先遍历
前序遍历
- 开始遍历:从 BST 的根节点开始。根节点是树的入口点,也是遍历的起始点。
- 访问根节点:首先访问根节点,这通常意味着读取或打印根节点中的值。在先序遍历中,根节点是最先被访问的。
- 遍历左子树:接下来,对根节点的左子树进行递归的先序遍历。如果存在左子节点,递归调用先序遍历函数,然后该子节点成为新的 “根”,重复步骤 2 和 3。
- 遍历右子树:左子树的所有节点都被访问后,再对根节点的右子树进行递归的先序遍历。同样,如果存在右子节点,递归调用先序遍历函数。
- 递归结束条件:当当前节点没有左子节点或右子节点时(即当前节点为叶子节点),或者当前节点为
NULL,递归调用结束。 - 返回到上一级节点:每次递归调用结束后,控制权返回到上一级节点的下一个操作,即上一级节点的右子树遍历(如果有的话)。
- 遍历完成:当所有节点都被访问且递归调用完全结束后,整个 BST 的先序遍历完成。
static void preorder(TreeNode* root) {
// 1.递归的出口
if (root == NULL) {
return;
}
// 2.递归体
printf("%d ", root->key);
preorder(root->left);
preorder(root->right);
}
void bst_preorder(BST* tree) {
if (tree == NULL) {
// 树为空直接返回
return;
}
// 利用辅助函数递归实现BST的先序遍历
preorder(tree->root);
printf("\n");
}
中序遍历
- 递归出口:遍历从根节点开始,但递归出口是当节点为
NULL时。如果当前节点为空,即没有更多的子节点可以遍历,递归调用结束。 - 遍历左子树:首先,递归调用中序遍历函数遍历当前节点的左子树。由于中序遍历先访问左子树,这确保了所有比当前节点值小的节点都会先被访问。
- 访问根节点:左子树遍历完成后,访问当前节点本身。这通常意味着读取或打印当前节点中的值。在中序遍历中,根节点在左子树之后被访问。
- 遍历右子树:然后,递归调用中序遍历函数遍历当前节点的右子树。由于中序遍历最后访问右子树,这确保了所有比当前节点值大的节点都会在根节点之后被访问。
- 递归体:中序遍历的递归体由三部分组成:首先是对左子节点的递归调用,然后是根节点的访问,最后是对右子节点的递归调用。
- 遍历结束:当所有节点都被访问且递归调用完全结束后,整个 BST 的中序遍历完成。
static void inorder(TreeNode* root) {
// 1.递归的出口
if (root == NULL) {
return;
}
// 2.递归体
inorder(root->left);
printf("%d ", root->key);
inorder(root->right);
}
void bst_inorder(BST* tree) {
if (tree == NULL) {
// 树为空直接返回
return;
}
// 利用辅助函数递归实现BST的中序遍历
inorder(tree->root);
printf("\n");
}
后序遍历
- 递归出口:遍历从根节点开始,但递归出口是当节点为
NULL时。如果当前节点为空,即没有更多的子节点可以遍历,递归调用结束。 - 遍历左子树:首先,递归调用后序遍历函数遍历当前节点的左子树。这确保了所有比当前节点值小的节点都会先被访问。
- 遍历右子树:左子树遍历完成后,递归调用后序遍历函数遍历当前节点的右子树。这确保了所有比当前节点值大的节点都会在左子树之后被访问。
- 访问根节点:在左子树和右子树的所有节点都被访问之后,访问当前节点本身。这通常意味着读取或打印当前节点中的值。在后序遍历中,根节点是最后被访问的。
- 递归体:后序遍历的递归体由三部分组成:首先是对左子节点的递归调用,然后是对右子节点的递归调用,最后是根节点的访问。
- 遍历结束:当所有节点都被访问且递归调用完全结束后,整个 BST 的后序遍历完成。
static void postorder(TreeNode* root) {
// 1.递归的出口
if (root == NULL) {
return;
}
// 2.递归体
postorder(root->left);
postorder(root->right);
printf("%d ", root->key);
}
void bst_postorder(BST* tree) {
if (tree == NULL) {
// 树为空直接返回
return;
}
// 利用辅助函数递归实现BST的后序遍历
postorder(tree->root);
printf("\n");
}
广度优先遍历
广度优先搜索(Breadth-First Search, BFS)是一种遍历树或图的算法,其按照层级顺序访问每个节点,因此也称为层次遍历。以下是层次遍历的实现过程:
- 初始化队列:首先,定义一个队列,其元素类型为二叉树节点的指针。
- 根节点入队:将二叉树的根节点(如果存在)添加到队列中。
- 开始循环:当队列非空时,执行以下步骤:
- 从队列中取出(出队)一个节点,这将是当前正在访问的节点。
- 打印当前节点的值或执行其他所需的操作。
- 子节点入队:对于当前出队的节点,按照从左到右的顺序,如果存在左子节点,则将其添加到队列中。接着,如果存在右子节点,也将它添加到队列中。
- 继续循环:重复步骤 3 和 4,直到队列中的所有节点都被出队,这意味着所有节点已经被按照层次顺序访问。
- 遍历结束:当队列为空时,层次遍历结束,此时树中的所有节点都已被访问。
“`c++
void bst_levelorder(BST *tree) {
LinkedListQueue *q = create_queue(); // 创建一个队列
// 首先让根结点入队
enqueue(q, tree->root);
// 当队列不为空时,执行循环
// 在这个循环中,我们将会逐个访问每一层的节点,并将它们的子节点加入队列
while (!is_empty(q)) {
// 刚进入 while 循环时,队列的 size 属性就是这一层结点的个数
int level_size = q->size; // 当前层次结点的个数
// 于是下面循环出队列 n 次,就是出队打印完所有本层结点,并将所有下一层结点都入队
for (int i = 0; i < level_size; i++) {
TreeNode *node = dequeue(q); // 出队获取当前结点
printf("%d ", node->key); // 打印当前节点的键值
// 如果当前节点的左子节点存在,将左子节点加入队列
if (node->left != NULL) {
enqueue(q, node->left);
}
// 如果当前节点的右子节点存在,将右子节点加入队列
if (node->right != NULL) {
enqueue(q, node->right);
}
}
// 出队打印完一层,换行
printf("\n");
}
printf("\n");
destroy_queue(q); // 完成遍历后,销毁队列释放资源
}
层次遍历的特点是它能够保证按照节点的物理结构顺序访问,即先访问上层节点,然后按从左到右的顺序逐层向下访问。这种遍历方式在需要按层处理节点或寻找特定层级上的节点时非常有用,例如在网络通信、操作系统的调度和树结构的可视化表示中。
### 二叉树的销毁操作
在进行二叉搜索树的销毁操作时的目标是确保释放所有分配的内存,以避免内存泄漏。为了实现这一点,选择后序遍历作为销毁节点的遍历方式,因为它首先访问子节点,最后访问根节点。
**销毁操作的步骤如下:**
1. **选择遍历方式**:后序遍历是销毁操作的理想选择,因为它保证了在释放父节点之前,其所有子节点都已经被访问和释放。
2. **递归释放节点**:通过递归调用,我们首先遍历并释放左子树的所有节点,然后是右子树的所有节点。
3. **释放根节点**:在所有子节点被释放之后,释放当前根节点的内存。
4. **递归出口**:当递归到达一个空节点(`NULL`)时,递归结束。
```c
// 递归释放BST的结点,总是最后释放根结点,所以采用后序遍历的方式实现
static void destory(TreeNode *root) {
if (root == NULL) {
return;
}
// 后序,先访问左右子树,再 free 根结点
destory(root->left);
destory(root->right);
free(root);
}
void bst_destroy(BST *tree) {
if (tree == NULL) {
return;
}
// 递归释放树结点
destory(tree->root);
free(tree);
}
二叉搜索树的性能分析

对于一个二叉搜索树(BST),其插入、查询和删除操作的效率确实依赖于树的高度 h。时间复杂度可以表示为 O(h)。
对于一个含有 n 个节点的二叉搜索树,其高度的确定如下:
- 最佳情况:当 BST 是一个完全二叉树时,其高度最小。完全二叉树的定义是每一层都被完全填满,除了可能的最后一层,且最后一层的节点尽可能地向左填充。在这种情况下,树的高度 h 可以通过 h = ⌊\log2(n)⌋+1 来估算,其中 ⌊⌋ 表示向下取整。
- 最差情况:当 BST 退化为一个链表时,其高度最大,即树的高度等于节点数 n。
因此,对于一个含有 n 个节点的二叉搜索树,其操作的时间复杂度为:
- 最佳情况:O(⌊\log2(n)⌋+1),简化为 O(log n)。
- 最差情况:O(n)。
为了确保 BST 的操作时间复杂度保持在 O(log n),我们需要在插入和删除节点后进行一些调整,以确保树的高度保持在 ⌊log 2 (n)⌋ 左右。这种能够自我调整以保持平衡的二叉搜索树被称为自平衡二叉搜索树或平衡二叉树。常见的平衡二叉搜索树有 AVL 树和红黑树等,它们通过特定的旋转操作或其他机制来维持树的平衡。