
字符串
字符串的本质
在 C 语言中,字符串字面值是一种特殊的数据表示形式,其本质是以空字符('\0')结尾的字符数组。
字符串字面值通常存储在程序的 数据段 中。数据段是程序内存布局的一部分,用于存储程序的全局变量和静态变量。
数据段可以进一步细分为两个区域:
1. 静态数据段:存储程序中的静态数据,如全局变量和静态局部变量。这个区域的数据具有可读可写的特性。
2. 只读数据段:存储程序中只能读取、不可修改的常量。字符串字面值的字符数组就存储在这个区域,其数据是只读的。
字符串字面值的字符数组具有 静态存储期限,这意味着它们从程序开始执行时就存在,直到程序结束。这种存储期限确保了字符串字面值在整个程序执行期间都是可用的。
字符串字面值的特点
存储特性:字符串字面值在本质上是存储在只读数据段中的字符数组,它们以空字符('\0')结尾。
生命周期:字符串字面值具有静态存储期限,这意味着它们从程序开始执行时就存在,直到程序结束。
只读性:字符串字面值是只读的,任何尝试修改这些值的操作都会导致未定义行为,通常会引发程序崩溃。
使用角度:在大多数情况下,字符串字面值可以被视为存储在只读数据段中的字符数组,数组名作为首元素的指针。
特殊情况下的指针表示:在某些场景中,字符串字面值不能直接作为首元素指针使用。例如,使用 sizeof 运算符时,它表示的是整个字符数组的大小,而不是指针。例如:
int len = sizeof("hello"); // 'len' 此时得到的是数组的大小,即 6 字节
函数参数传递:当函数需要接收字符串字面值作为参数,并且确保不修改其内容时,函数的形参通常会声明为 const char* 类型。例如:
void processString(const char* str) {
// 函数体中 'str' 不能被修改
}
为了避免意外修改字符串字面值,应使用 const 关键字。这不仅是一种良好的编程实践,也有助于编译器进行优化。
字符串的特点
C 语言没有专门的字符串类型,而是使用以空字符('\0')结尾的一维字符数组来表示字符串。
C 语言字符串设计的特点:
- 优点:
- 设计简洁统一,无需引入新的数据类型。
- 空间占用较小,因为只存储字符数据和空字符。
- 缺点:
- 无法直接确定字符数组是否为字符串,除非通过遍历查找空字符。
- 空字符作为字符串结束的标志,需要在处理时进行特殊考虑。
- 字符串不包含空字符,但空字符是字符串结束的必要标记。
- 最主要的问题是,C 语言的字符串不存储长度信息,获取长度需要遍历字符串,这可能对长字符串的处理效率较低。
- 字符串长度获取:获取 C 语言字符串长度的常见方法是使用
strlen()函数,该函数遍历字符串直到找到空字符。 -
后续编程语言的改进:
- 许多后续的编程语言,如 C++、Java、C#、Go、Python 等,提供了独立的
String类型。 -
这些语言中的
String类型通常将字符串长度作为其属性之一,便于在操作时直接获取。 -
C 语言基于其简洁统一的设计哲学,选择了不设计专属的字符串类型,但这种做法带来了一些弊端。
- 其他编程语言在设计字符串类型时,考虑到了这些弊端,并提供了更为方便和高效的字符串处理方式。
字符串的声明
在 C 语言中,字符串可以通过两种主要方式声明为字符串变量:
- 字符数组声明:
- 使用格式
char str[长度];声明一个具有固定长度的字符数组。 - 这种声明方式适用于函数内部,此时字符数组作为局部变量在栈上分配空间。
- 一旦声明,数组的长度是固定的,但数组中的字符内容是允许被修改的。
- 适用于已知字符串内容且长度不变的场景。
- 使用格式
- 字符指针声明:
- 使用格式
char *str;声明一个字符指针变量。 - 如果声明在函数内部,该指针作为局部变量,但未初始化时是一个野指针。
- 字符指针具有很高的灵活性,可以指向任意类型的字符串。
- 特别适用于需要动态内存分配的场景。
- 使用格式
根据以上的声明格式,我们有两种初始化语句:
- 字符数组初始化:
char str[] = "hello";- 这行代码在函数体内部声明了一个字符数组
str并使用字符串字面值 “hello” 进行初始化。 - 字符串字面值 “hello” 实际上被视为字符数组
{'h', 'e', 'l', 'l', 'o', '\0'}的简写形式。 - 由于
str是数组名,可以使用它来修改字符串中的字符,但不能使用str = "world";这样的语句重新赋值一个新字符串。
- 这行代码在函数体内部声明了一个字符数组
- 字符指针初始化:
char *pstr = "hello";- 这行代码声明了一个字符指针
pstr并将其初始化为指向字符串字面值 “hello” 的指针。 - 字符串字面值 “hello” 存储在只读数据段中,因此不允许通过
pstr修改字符串内容。 - 但是,作为指针,
pstr可以被重新赋值指向另一个字符串字面值。
- 这行代码声明了一个字符指针
区别:
char str[] = "hello";分配的内存是一个连续的字符数组内存块,允许修改字符串内容,但不能重新赋值整个字符串。char *pstr = "hello";分配的是一个普通的字符指针变量,指向存储在只读数据段中的字符串字面值,不允许修改字符串内容,但可以改变指针的指向。
选择使用字符数组还是字符指针取决于具体的应用场景和需求。字符数组提供了修改字符串内容的能力,而字符指针则提供了更高的灵活性。
字符串数组
在 C 语言中,字符串数组是一种用于存储多个字符串的容器。由于 C 语言中的字符串实际上是以空字符('\0')结尾的字符数组,因此字符串数组可以采用两种不同的存储方式:
- 二维字符数组形式:
- 字符串数组可以被实现为一个二维字符数组,其中每个子数组都代表一个字符串。
- 这种实现方式直观地将每个字符串存储为数组中的一行。
- 指针数组形式:
- 另一种实现方式是使用指针数组。在这种方式中,每个字符串被视为一个字符数组的首元素指针,而指针数组则存储这些指针。
- 这种方法利用了 C 语言中数组名可以被视为指向数组首元素的指针的特性。
二维数组形式
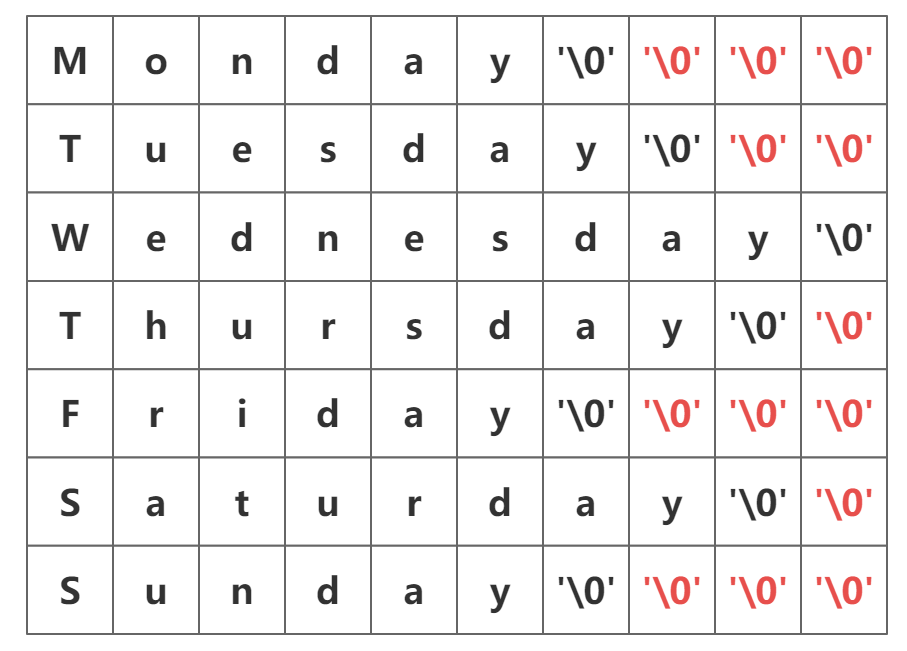
在 C 语言中,可以使用 char 类型的二维数组来实现字符串数组。这种实现方式在内存中是连续存储的,类似于一个矩阵。
尽管在概念上可以视为矩阵,但实际上这些字符串在内存中是连续排列的。这意味着所有的字符串都存储在一块连续的内存区域中。在这种实现方式中,二维数组的列长必须是固定的,即每个字符串的最大长度是相同的。这可能导致空间浪费,因为较短的字符串后面会有多余的空字符。
- 优点:
- 简单直观,易于理解。
- 由于内存连续存储,访问效率高。
- 缺点:
- 空间浪费:较短的字符串会占用更多的空间。
- 操作繁琐:对于需要动态操作(如排序、删除)的字符串数组,二维数组实现起来比较麻烦。
如果需求是处理一个固定的数据集,不需要动态地新增、修改或删除字符串,只是需要访问,那么这种实现方式是高效的。
指针数组形式
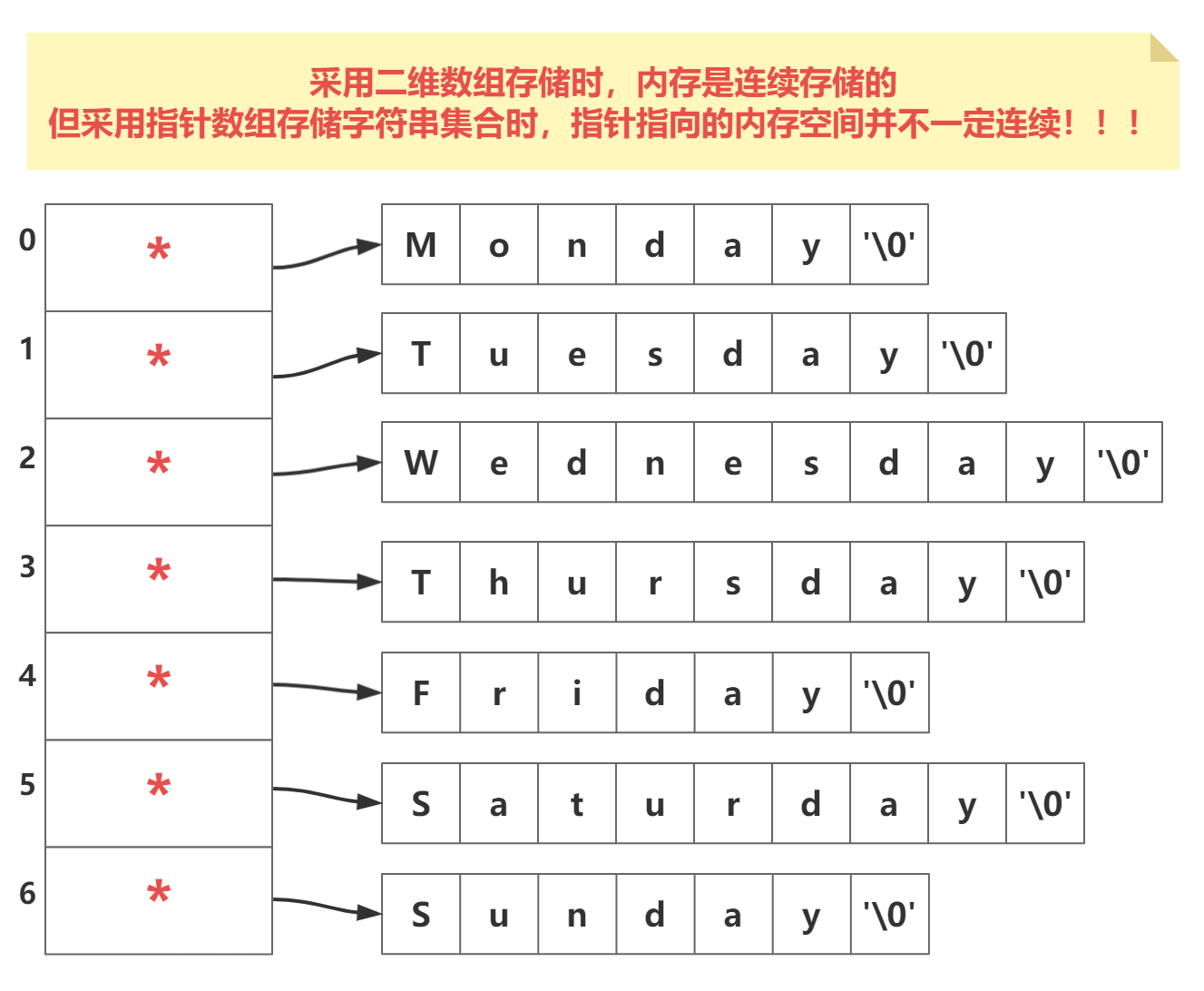
在 C 语言中,char* 类型的指针数组是一种常用的实现字符串数组的方式。每个指针元素指向一个字符数组,这个字符数组代表一个字符串。
指针数组的内存空间是连续的,但每个指针指向的字符串可能存储在内存的不同位置。因此,虽然指针数组内部是连续的,但它们指向的字符串所在的内存空间是不连续的。
- 优点:
- 空间利用:指针数组不会像二维字符数组那样浪费空间,因为每个字符串可以有不同长度。
- 操作便利:对字符串的操作实际上是对字符指针的操作。字符串的新增、删除、移动等操作只需要操作指针变量,非常简单且高效。
- 缺点:
- 访问效率:由于内存空间的不连续,访问指针数组中的字符串可能不如二维数组高效。
指针数组在需要对字符串数据集进行频繁的增删、排序等操作时非常有用。由于操作上的便利性,指针数组在实际应用中更常用于实现字符串数组。
Java 的二维数组在实现上与 C 语言的指针数组不同。Java 的二维数组实际上是一个数组的数组,每个数组元素都是一个指向字符数组的指针。
字符串常用操作
输出字符串到标准输出(stdout)的函数
C 语言中,有几个函数可以用来将字符串输出到标准输出缓冲区:
putchar() 函数:putchar() 用于将单个字符输出到 stdout。函数名来源于 “put character”,即输出字符。
puts() 函数:puts() 用于将一个字符串输出到 stdout。函数名来源于 “put string”,即输出字符串。与 printf() 函数相比,puts() 会在输出的字符串末尾自动添加一个换行符。
性能建议:如果目标是简单地将一个字符串输出到终端并换行,推荐使用 puts() 函数。因为它是 printf() 函数的特化版本,专门用于输出字符串,并且在这种情况下性能可能更优。
遍历字符串并逐个输出字符的惯用方法
- 声明和初始化字符串:;
str是一个字符数组,存储了要遍历的字符串。 - 使用字符指针遍历: 声明一个字符指针
q并初始化为指向字符串的起始位置。 - while 循环遍历: 使用
while循环遍历字符串,条件是*q不是空字符('\0'); 循环体内可以放置对当前字符的处理代码,q++用于移动指针到下一个字符。 - 注意事项:
- 指针
q的类型必须是char*类型,以便正确地解引用并访问字符。使用int*类型或其他非字符指针类型将导致未定义行为。 - 如果在
while循环中使用*q++结构,需要特别注意循环结束后q指针的位置。此时,q将指向空字符之后的字符。
- 指针
#include <stdio.h>
int main() {
char str[] = "Genshin";
char *q = str;
while(*q) { // 循环直到遇到空字符
putchar(*q); // 输出当前字符
q++; // 移动到下一个字符
}
putchar('\n'); // 换行
return 0;
}
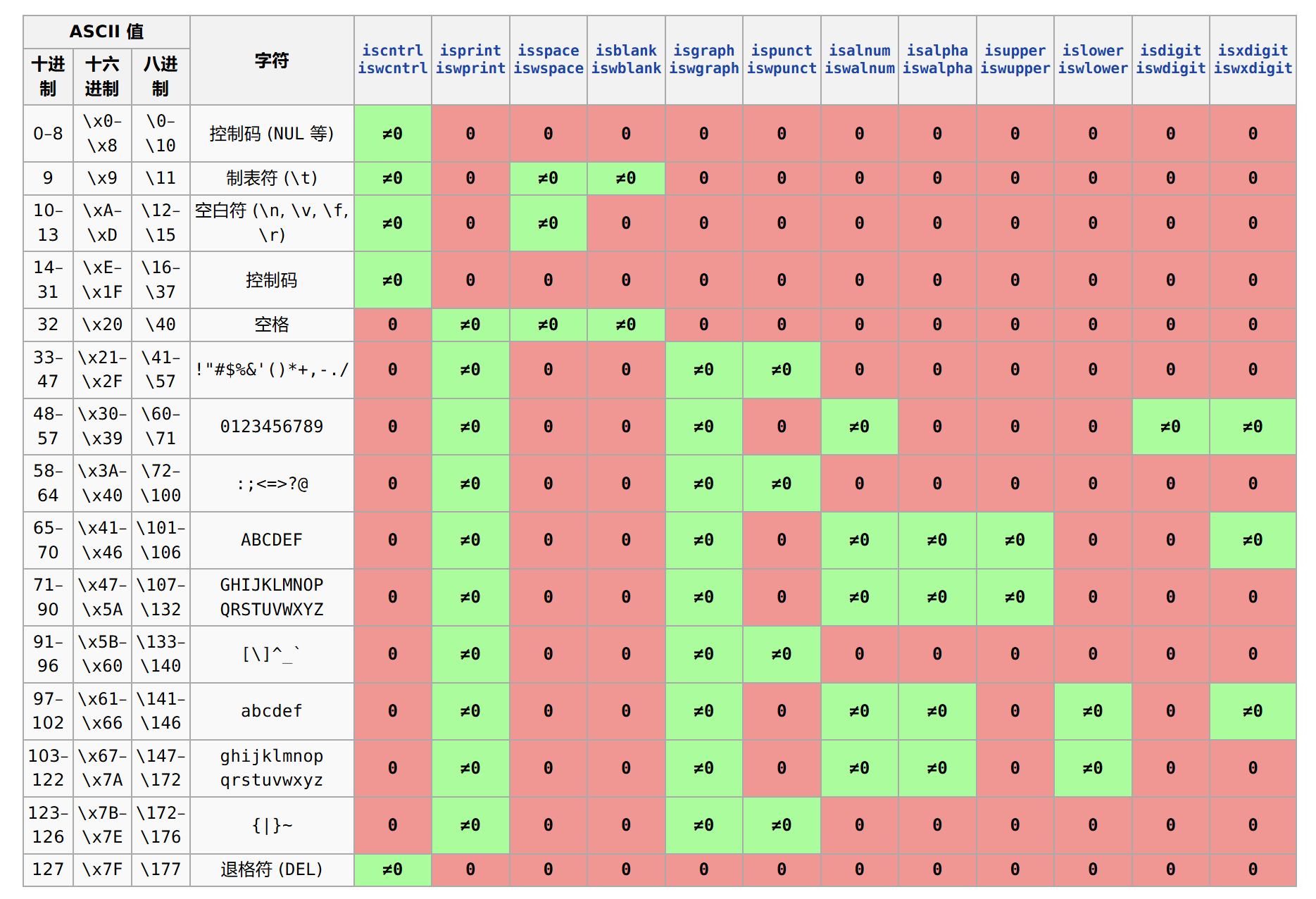
判断字符的类型及原理的剖析
判断一个字符是否为数字
数字字符(’0′ 至 ‘9’)在 ASCII 码表中对应的值是从 48 到 57。这意味着,如果一个字符的 ASCII 码值落在这个范围内,那么它就是一个数字字符。
#include <stdio.h>
int IsDigital(char temp){
return temp >= '0' && temp <= '9';
}
int main() {
printf("%d \n", IsDigital('1')); // 1
printf("%d \n", IsDigital('2')); // 1
printf("%d \n", IsDigital('3')); // 1
printf("%d \n", IsDigital('A')); // 0
return 0;
}
判断字符是大写字母,小写字母,空格,还是其他字符
在 C 语言中,判断字符是否为大写字母、小写字母、空格或其他字符,通常借助于标准库中的 <ctype.h> 头文件。这个头文件提供了一系列的函数,用于检查字符的类型,并根据检查结果返回布尔值:如果是真(即字符符合指定类型),返回非零值;如果是假(即字符不符合指定类型),返回零。
#include <stdio.h>
#include <ctype.h>
int main() {
printf("%d \n", isdigit('1')); // 4 判断是否是数字
printf("%d \n", isspace(' ')); // 8 判断是否是空格
printf("%d \n", isalpha('a')); // 2 判断是否是字母
printf("%d \n", isalnum('A')); // 1 判断是否是字母或者数字
printf("%d \n", isalnum('2')); // 4 判断是否是字母或者数字
printf("%d \n", ispunct(';')); // 16 判断是否是标点符号
return 0;
}
编译器内部实现这些函数时,通常会使用查表的方法来提高效率。这种方法比一系列的条件判断更为高效,尤其是在需要同时检查多个条件时。查表的方法可以快速地通过字符的 ASCII 码值索引到一个预定义的表中,从而确定字符的类型。
使用查表而不是条件判断的原因主要在于性能。在处理大量字符时,查表可以提供更快的查找速度,因为它减少了条件判断所需的逻辑分支。这种方法在编译器优化中是一种常见的实践。
字符转换大小写
char temp = 'A';
printf("%c\n", tolower(temp)); // a
char temp2 = 'a';
printf("%c", toupper(temp2)); // A
字符串常用 api
字符串与其他数值类型的转换
字符串类型转换为其他类型(例如 int,double 等)
在 C 语言中,可以使用标准库函数将字符串转换为基本数值类型,如 int、double 等。以下是一些常用的转换函数:
atof(const char *nptr):将字符串nptr转换为double类型。atoi(const char *nptr):将字符串nptr转换为int类型。atol(const char *nptr):将字符串nptr转换为long类型。atoll(const char *nptr):将字符串nptr转换为long long类型。_atoi64(const char *nptr):将字符串nptr转换为__int64类型(特定编译器支持)。
MSVC 源码如下:
_Check_return_ _ACRTIMP double __cdecl atof (_In_z_ char const* _String);
_Check_return_ _CRT_JIT_INTRINSIC _ACRTIMP int __cdecl atoi (_In_z_ char const* _String);
_Check_return_ _ACRTIMP long __cdecl atol (_In_z_ char const* _String);
_Check_return_ _ACRTIMP long long __cdecl atoll (_In_z_ char const* _String);
_Check_return_ _ACRTIMP __int64 __cdecl _atoi64(_In_z_ char const* _String);
GCC 源码如下:
int atexit (void (*__func)(void));
double atof (const char *__nptr);
#if __MISC_VISIBLE
float atoff (const char *__nptr);
#endif
int atoi (const char *__nptr);
int _atoi_r (struct _reent *, const char *__nptr);
long atol (const char *__nptr);
long _atol_r (struct _reent *, const char *__nptr);
atoi 函数会忽略字符串开头的空白字符,直到遇到第一个非空白字符。如果该字符不能转化为数字,则转换过程停止,函数返回当前已识别的整数值。
#include <stdio.h>
#include <stdlib.h>
int main() {
printf("%d\n", atoi("1234")); // 1234
printf("%d\n", atoi("-1234")); // -1234
printf("%d\n", atoi(" 12 34abcd12")); // 12
printf("%d\n", atoi("0x10")); // 0
printf("%d\n", atoi(" a1234abcd12")); // 0
return 0;
}
atof 函数同样会忽略字符串开头的空白字符,直到遇到第一个非空白字符。与 atoi 不同的是,atof 可以处理浮点数,包括小数点和指数部分。
#include <stdio.h>
#include <stdlib.h>
int main() {
// msvc 编译器的结果
printf("%f\n", atof("1234")); // 1234.000000
printf("%f\n", atof("-12e34")); // -120000000000000007304085773727301632.000000
printf("%f\n", atof(" 12 34abcd12")); // 12.000000
printf("%f\n", atof(" a1234abcd12")); // 0.000000
printf("%f\n", atof("0x10")); // 16.000000
// 16 进制数仿照十进制使用科学计数法 (a*10^n) 的例子
// 0x10 就是 a,而后面 p 跟着的不是 10 ^ n,是 2 ^ n,n 必须为整数,所以这里 n = 3.9 会自动被当为 n = 3,16 * 8 = 128
printf("%f\n", atof("0x10p3.9")); // 128.000000
return 0;
}
在 MSVC 编译器下,atof 函数可能支持将十六进制字符串转换为浮点数。然而,这并不是所有编译器都支持的行为。
在 GCC 编译器下,atof 函数不支持十六进制浮点数的转换。因此,使用 atof 转换十六进制字符串(如 "0x10" 或 "0x10p3.9")将不会得到预期的浮点数值,而是返回 0.000000。
字符串类型转换为其他类型(strto 函数)
strtol和strtoll:- 这两个函数用于将字符串转换为有符号的长整型(
long和long long)。 - 它们考虑了字符串中的基数,可以转换十进制、十六进制(以 “0x” 开头)和八进制(以 “0” 开头)的字符串。
- 这两个函数用于将字符串转换为有符号的长整型(
strtoul和strtoull:- 这两个函数用于将字符串转换为无符号的长整型(
unsigned long和unsigned long long)。 - 与
strtol和strtoll类似,它们也支持不同基数的字符串转换。
- 这两个函数用于将字符串转换为无符号的长整型(
strtof、strtod和strtold:- 这些函数用于将字符串转换为浮点型,分别对应
float、double和long double类型。 - 它们可以转换包含小数点和指数部分的字符串。
- 这些函数用于将字符串转换为浮点型,分别对应
strtoimax和strtoumax:- 这两个函数用于将字符串转换为
intmax_t类型,这是所在环境中表示范围最大的整数类型。 - 它们定义在
<stdint.h>头文件中,而不是<cstdlib>或<stdlib.h>。 strtoimax用于有符号整数转换,而strtoumax用于无符号整数转换。
- 这两个函数用于将字符串转换为
使用 strtol() 系列函数时的注意事项:
- 这些函数会更新一个指针参数,指向字符串中第一个无法转换为数值的字符。
- 如果转换失败,它们会设置
errno来指示错误类型。 strtol系列函数比atoi系列函数更灵活,因为它们可以处理不同基数的数值字符串,并且提供了更丰富的错误处理机制。
ato 函数和 strto 的区别
ato函数的特点:ato函数使用简单,适用于快速转换,但功能相对有限。- 当遇到无法解析的字符时,
ato函数会停止转换并返回当前已解析的数值。
strto函数的特点:strto函数虽然使用更为复杂,但提供了更丰富的功能:- 当字符串转换失败时,
strto可以通过设置errno(错误编号)来获取失败的错误代码,并且会返回相应数值类型的最大或最小边界值。 strto允许指定基数进行整数转换,这使得它可以处理不同进制的数值字符串。strto函数支持在一次调用中多次解析数字,这适用于字符串中包含多个可解析数字的场景。例如,对于字符串 “a123″,atoi会返回 0,因为 ‘a’ 不是数字,而strto函数可以解析并返回 “123”。
- 当字符串转换失败时,
strto 函数的具体使用
strtol() 函数的使用细节:
strtol() 函数是一种用于将字符串转换为长整型(long)的函数,它提供了比 atoi() 更高级的字符串解析功能。该函数接受三个参数:
- 源字符串的起始地址:这是要转换的字符串的起始位置。
- 字符指针的指针(通常命名为
endptr):这个指针用于存储转换结束的位置,即指向字符串中第一个无法识别为数字的字符。 - 进制:这是要转换的数字的基数,例如,10 表示十进制,16 表示十六进制。
使用流程:
- 首先,
start指向字符串的起始地址。 strtol()函数从start开始解析字符串,直到遇到无法转换为数字的字符。- 解析结束后,
strtol()将更新endptr指向的地址,使其指向字符串中的第一个非数字字符。 - 如果需要继续解析字符串中的下一个数字,可以将
endptr所指向的位置赋值给start,然后重复上述解析过程。 - 如果
endptr的值没有变化,或者它指向了字符串的末尾,这表明所有可解析的数字已经被转换。
#include <stdio.h>
#include <stdlib.h>
int main() {
char const *const KInput = "1 200000000000000000000000000000000000 3 -4 5abcd bye 122";
printf("%s", KInput);
char const *start = KInput;
char *end; // 注意,这里不用赋值,函数内部会修改 end 的值
while (1) {
// 从start位置开始,读取到end位置,然后继续end位置。读取进制为10进制
long value = strtol(start, &end, 10);
// 如果 strtol() 使用后,end指针位置不变,说明能读取的都读取了
if (start == end) {
break;
}
// 读出来的内容打印看下
printf("\n内容:%ld", value);
// 读取一个后,以end作为起始点
start = end;
}
return 0;
}
运行结果如下:
1 200000000000000000000000000000000000 3 -4 5abcd bye 122
内容:1
内容:9223372036854775807
内容:3
内容:-4
内容:5
- 对于字符串 “1 200000000000000000000000000000000000 3 -4 5abcd bye 122″,当解析第一个数字 “1” 后,
strtol()函数正确返回了数值 1。 - 接下来,函数尝试解析 “200000000000000000000000000000000000”,这是一个超出
long类型范围的数值。在这种情况下,strtol()函数返回了long类型的最大值,即 9223372036854775807(在 32 位系统中,这是2^63 - 1)。 - 随后,字符串中的 “3 -4 5” 被逐一解析并返回了相应的整数值 3 和 -4。
- 当遇到 “5abcd” 时,
strtol()在解析到 “5” 后停止,因为 “abcd” 不是有效的数字字符。此时,endptr指向 “abcd”,表示解析结束的位置。 - 最后,由于
endptr指向了 “abcd”,后续的数字 “122” 没有被解析,因为strtol()函数的解析过程已经在 “abcd” 处停止。
字符串的长度与比较
字符串长度的判断方法
在 C 语言中,字符串通常以空字符 '\0' 结尾。因此,可以通过查找空字符的位置来确定字符串的长度。C 语言提供了 strlen() 函数,用于直接获取字符串的长度。
strlen() 函数通过遍历字符串的每个字符来计数,直到遇到空字符 '\0'。此函数的使用简单直接,但如果字符串非常长,可能会存在一定的性能考虑
#include <stdio.h>
#include <string.h>
int main() {
char *string = "Hello World!";
printf("%d\n", strlen(string)); // 12
return 0;
}
为了提高安全性,C11 标准引入了 strnlen_s() 函数,该函数可以限制最大读取的字符数,从而避免潜在的缓冲区溢出问题。strnlen_s() 函数接受两个参数:待读取的字符串和最大读取字符数。
在 MSVC 编译器中,函数名为 strnlen_s(),而在 GCC 编译器中,函数名为 strnlen()。使用时应根据编译器选择合适的函数名。
printf("%d\n", strnlen_s(string, 100)); // 最多读取 100 个字符,msvc
printf("%d\n", strnlen(string, 100)); // gcc
字符串间的比较
在 C 语言中,字符串比较可以通过 strcmp() 和 strncmp() 函数实现。这两个函数用于比较两个字符串,并根据比较结果返回相应的整数值。
strcmp()函数:strcmp()函数逐个字符比较两个字符串,从左到右,直到发现两个不同的字符或遇到字符串的结尾(’\0’)。- 如果左侧字符串(lhs)在字典序上小于右侧字符串(rhs),返回
-1;如果大于,则返回1;如果两个字符串相同,则返回0。
strncmp()函数:strncmp()函数与strcmp()类似,但它只比较两个字符串的前count个字符。count是一个size_t类型的值,表示要比较的字符数的最大限制。
比较结果:
- 字典序比较基于字符的 ASCII 码值。如果两个字符串在前
count个字符内不相同,strncmp()函数的返回值与strcmp()相同。 - 如果比较的字符数达到
count,但两个字符串的对应子串相同,strncmp()返回0。
void TestCompare(){
char *left = "Hello W";
char *right = "Hello C";
printf("%d\n", strcmp(right, left)); // < -1
printf("%d\n", strcmp(left, right)); // > 1
printf("%d\n", strncmp(left, right, 5)); // = 0
}
将字符数组的所有元素按照字母表顺序排列
void SwapString(char * *a, char * *b) {
char *temp = *a;
*a = *b;
*b = temp;
}
char * *Partition(char * *low, char * *high) {
char *pivot = *(low + (high - low) / 2);
char * *p = low;
char * *q = high;
while (1) {
// while (*p < pivot) p++; 说明字典序情况下,p 在 pivot 前面
while (strcmp(*p, pivot) < 0) p++;
// while (*q > pivot) q--; 说明字典序情况下,q 在 pivot 后面
while (strcmp(*q, pivot) > 0) q--;
if (p >= q) break;
SwapString(p, q);
}
return q;
}
void QuickSort(char * *low, char * *high) {
if (low >= high) return;
char * *partition = Partition(low, high);
QuickSort(low, partition - 1);
QuickSort(partition + 1, high);
}
void CompareName(char *names[]) {
printf("排序前:");
for (int i = 0; i < 6; ++i) {
printf("%s\t", names[i]);
}
QuickSort(names, names + 5);
printf("\n排序后:");
for (int i = 0; i < 6; ++i) {
printf("%s\t", names[i]);
}
}
int main() {
char *names[] = {
"Andy",
"Don",
"Elsa",
"Alice",
"Ben",
"Frank",
};
CompareName(names);
return 0;
}
查找字符与子串
查找字符串中的一个字符
在 C 语言中,可以使用 strchr() 和 strrchr() 函数来查找字符串中出现的特定字符,并返回指向该字符的指针。
strchr()函数:strchr()函数从字符串的开始位置向左到右搜索第一次出现指定字符的位置。- 如果找到了指定的字符,函数返回一个指向该字符的指针;如果没有找到,返回
NULL。
strrchr()函数:strrchr()函数从字符串的末尾向右向左搜索最后一次出现指定字符的位置。- 与
strchr()类似,如果找到,返回指向该字符的指针;如果没有找到,返回NULL。
- 字符指定:
- 在调用
strchr()函数时,第二个参数是要查找的字符,其类型为int。因此,应使用单引号来指定字符,例如'A'或'1'。
- 在调用
#include <stdio.h>
#include <string.h>
void TestStrchr() {
char *result = strchr("hello world!", 'l'); // 注意,不能使用双引号:"l"
printf("result: %s\n", result); // llo world!
char *result_reverse = strrchr("hello world!", 'l');
printf("result_reverse: %s\n", result_reverse); // ld!
}
strpbrk() 函数的功能:
strpbrk() 函数是一个用于在字符串中搜索多个指定字符的函数。与 strchr() 和 strrchr() 函数不同,后者只搜索单个字符,strpbrk() 可以同时搜索一组字符。
- 函数定义:
strpbrk()函数搜索字符串中第一个出现在其第二个参数指定的字符集里的字符,并返回一个指针,指向该字符在字符串中的位置。 - 函数特点:
- 第一个参数是要搜索的源字符串。
- 第二个参数是一个字符集,包含了要搜索的字符集合。这个字符集可以是任何字符串,包括但不限于单个字符。
- 返回值:
- 如果找到匹配的字符,
strpbrk()返回指向该字符的指针。 - 如果没有找到任何匹配的字符,函数返回
NULL。
- 如果找到匹配的字符,
void TestStrpbrk() {
char *exp = "C, 1972; C++, 1983; Java, 1995";
char *p = exp;
int count = 0; // 记录 , 和 ; 的总个数
do {
char *break_set = ",;";
p = strpbrk(p, break_set); // 找不到,返回 NULL
if (p) {
// 找到了,打印,计数
count++;
printf("%s\n", p);
p++; // 跳过当前符号,否则会死循环。因为当前符号一定是 break_set 中的。
}
} while (p);
printf(",和;的总数为:%d", count);
}
输出结果为:
, 1972; C++, 1983; Java, 1995
; C++, 1983; Java, 1995
, 1983; Java, 1995
; Java, 1995
, 1995
,和;的总数为:5
strpbrk() 函数在循环中使用,可以遍历字符串并找到字符集中的每个字符出现的位置。通过修改循环条件和逻辑,strchr() 和 strrchr() 函数也可以应用于类似的统计任务,例如统计字符串中某个单一字符出现的次数。与 strpbrk() 相比,strchr() 和 strrchr() 在这种情况下统计的是单一字符类型的个数。
void TestStrpbrk() {
char *exp = "C, 1972; C++, 1983; Java, 1995";
char *p = exp;
int count = 0; // 记录 , 和 ; 的总个数
do {
p = strchr(p, '9'); // 找不到,返回NULL
if (p) {
// 找到了,打印,计数
count++;
printf("%s\n", p);
p++; // 跳过当前符号,否则会死循环。因为当前符号一定是 break_set 中的。
}
} while (p);
printf("count: %d\n", count); // count: 4
}
查找字符串的子串
在 C 语言中,可以使用 strstr() 函数来查找一个字符串(子串)在另一个字符串中首次出现的位置,并返回一个指向该位置的指针。
strstr()函数的使用:strstr()函数接受两个参数:要搜索的源字符串和要查找的子串。- 如果找到子串,函数返回指向源字符串中子串起始位置的指针;如果没有找到,返回
NULL。
- 计算子串的偏移量:
- 子串相对于原字符串的偏移量可以通过简单地从子串指针中减去原字符串指针来计算。
void TestStrstr() {
char *string_input = "hello world!";
char *sub_string = strstr(string_input, "wor");
printf("sub_string: %s\n", sub_string); // sub_string: world!
int offset = sub_string - string_input;
printf("offset: %d\n", offset); // 偏移量 offset: 6
}
字符串的拆分
将一个字符串按照给定符号进行拆分
trtok() 函数的字符串分割功能:
strtok() 函数用于分割字符串,它通过指定的分隔符将字符串分割成多个子字符串。该函数会修改原字符串,用空字符 '\0' 替换分隔符,从而实现分割。
- 函数行为:
strtok()函数的第一个参数是要分割的字符串。- 第二个参数是一个字符串,包含用作分隔符的字符集合。
- 分割过程:
- 当
strtok()遇到一个分隔符时,它会用'\0'替换该分隔符,从而将字符串分割成子字符串。
- 当
- 返回值:
strtok()返回第一个调用的结果,即第一个子字符串的首地址。- 后续调用应传入
NULL作为第一个参数,以获取后续的子字符串。
#include <stdio.h>
#include <string.h>
void TestStrtok() {
char *string1 = "C, 1972; C++, 1983; Java, 1995";
char *result = strtok(string1, ";");
printf("%s\n", result); // C, 1972
printf("length: %lu\n", strlen(result)); // length: 7
char *result2 = strtok(NULL, ";");
printf("%s\n", result2); // C++, 1983 注意,这里的 C 前面有个空格,因为原字符串分号之后是空格
printf("length: %lu\n", strlen(result2)); // length: 10
}
将字符串按给定的多个符号进行拆分
结构体指针,结构体数组本质相同。定义为 Language *languages,但在使用时,仍然按照 languages[i] 这种数组形式来使用。
void TestStrtok2() {
char *string1 = "C, 1972; C++, 1983; Java, 1995";
// 一个结构体接收一个子字符串,结构体数组接收全部的字符串
typedef struct Language {
char *name;
int year;
} Language;
// 按照分号和逗号进行分割
char const *language_break = ";";
char const *filed_break = ",";
// 由于拆分后的字符个数未知,Language数组使用动态内存
int language_capacity = 3; // 默认数组总大小
int language_size = 0; // 已放入language数组中的子字符串的个数
// 结构体数组,结构体指针本质相同 languages
Language *languages = malloc(sizeof(Language) * language_capacity);
// 分配内存失败时,程序强制退出
if (!languages) {
abort();
}
// 先按照逗号拆
char *next = strtok(string1, filed_break);
while (next) {
// 定义一个language
Language language;
// next指针不断后移,每次调用strtok函数一次,就后移一次。
language.name = next;
char *year_str = strtok(NULL, language_break); // 逗号拆完拆分号
if (year_str) {
// 每次拆分结束,都需要判断一下
language.year = atoi(year_str); // 年份是字符,需要进行转换
}
// 将定义的 language 放入到 languages 中去.加入之前,不要忘记判断内存大小是否足够
if (language_size + 1 >= language_capacity) {
// 一般来说,好像会空一个,所以 +1
language_capacity = language_capacity * 2;
languages = realloc(languages, sizeof(Language) * language_capacity);
if (!languages) {
// 内存分配失败,强行停止
abort();
}
}
languages[language_size++] = language; // 将定义的 language 放入到 languages 中
next = strtok(NULL, filed_break);
}
// 字符串拆分结束
printf("language_capacity: %d\n", language_capacity);
printf("language_size: %d\n", language_size);
for (int i = 0; i < language_size; ++i) {
printf("name: %s, year: %d\n", languages[i].name, languages[i].year);
}
// 使用过的内存要释放
free(languages);
}
字符串的连接和复制
如何拼接两个字符串
在 C 语言中,可以使用 strcat() 函数来拼接两个字符串。该函数将第二个字符串拼接到第一个字符串的末尾。
strcat() 函数的使用:
strcat()函数接受两个参数:目标字符串和要拼接的源字符串。- 函数会修改目标字符串,在其末尾追加源字符串的内容。
void TestStrcat() {
char *string1 = "Hello";
char *string2 = "World";
strcat(string1, string2);
printf("string1: %s\n", string1); // 输出: string1: HelloWorld
printf("string2: %s\n", string2); // 输出: string2: World
}
注意事项:
- 使用
strcat()函数时,需要确保目标字符串有足够的空间来存储拼接后的字符串,否则可能导致缓冲区溢出。 - 在示例中,
string1存储在栈区,而string2指向的是一个常量字符串,位于常量区。使用const限定符可以防止对string2的修改。
在 MSVC 编译器中,如果 string1 和 string2 都指向相同的内存区域(例如,它们都是字符串字面量),使用 strcat() 可能会导致 string2 的内容被覆盖。因此,应避免在 strcat() 中使用字符串字面量作为目标字符串。
拼接前:

拼接后:

若此时读取 string2,其结果为 “6c 64 00 6c 64 00 00 00″,由于 00 是字符串结束标志,所以只能打印 “6c 64” 对应的内容,为 “ld”。
代码的正确写法如下,此时,string1 存储在栈区,string2 指向的内容存储在常量区。
void TestStrcat() {
char string1[20] = "Hello";
char *string2 = "World";
strcat(string1, string2);
printf("string1: %s\n", string1); // string1: HelloWorld
printf("string2: %s\n", string2); // string2: World
}
字符串的复制
strcpy() 函数用于将一个字符串复制到另一个字符串的起始位置。
strcpy() 函数的使用:
strcpy()函数接受两个参数:目标字符串和源字符串。- 函数会从目标字符串的起始位置开始复制源字符串的所有字符,包括结尾的空字符
'\0'。
#include <stdio.h>
#include <string.h>
void TestStrcpy() {
char string1[20] = "Hello C++";
const char *string2 = "World";
strcpy(string1, string2);
printf("string1: %s\n", string1); // 输出: string1: World
// string2 的内容不会改变,因为它是一个指向常量字符串的指针
printf("string2: %s\n", string2); // 输出: string2: World
}
int main() {
TestStrcpy();
return 0;
}
注意,使用 strcpy() 函数时,需要确保目标字符串有足够的空间来存储源字符串的全部内容,包括结尾的空字符,以避免缓冲区溢出。
如果需要将字符串复制到目标字符串的中间位置,可以通过计算偏移量来实现。例如,将源字符串复制到目标字符串末尾:
void TestStrcpy2() {
char string1[20] = "Hello";
const char *string2 = " World"; // 注意添加空格以匹配原始 string1 的长度
strcpy(string1 + strlen(string1), string2); // 从 string1 的末尾开始复制
printf("string1: %s\n", string1); // 输出: string1: Hello World
// string2 的内容不会改变
printf("string2: %s\n", string2); // 输出: string2: World
}
C 语言中的 char * 和 char [ ]
在 C 语言中,char * 和 char[] 都用于处理字符数据,但它们之间存在一些关键的区别:
char *指针:
char *定义的是一个指向字符的指针。- 如果
char *指针被初始化为一个字符串字面量(如char *string1 = "hello";),它指向的是存储在常量区的只读内存。尝试修改这些内存中的值将导致未定义行为,在某些编译器(如 GCC 或 MinGW )上可能会引发警告或程序崩溃。 - 在 MSVC 编译器下,尽管可能不会立即警告,但这种行为仍然是不安全的,因为它违反了内存的只读属性。
char[]数组:
char[]定义的是一个字符数组。- 字符数组存储在栈上,其内容是可写的,可以安全地进行修改。
- 内存安全性:
- 使用
char *指针时,应当确保不会意外修改指向的只读数据。 - 使用
char[]数组时,由于其存储在栈上,可以自由地修改数组中的元素。
- 示例代码:
GCC 编译器下,改代码无法运行
#include <stdio.h>
void TestChar() {
// 安全的字符数组示例
char stringArray[6] = "hello";
stringArray[0] = 'a'; // 修改第一个字符
stringArray[1] = 'b'; // 修改第二个字符
printf("%s\n", stringArray); // 输出: abllo
// 不安全的字符指针示例(不推荐)
const char *stringConst = "hello"; // 使用 const 限定符
// *stringConst = 'a'; // 这将导致编译错误,因为尝试修改常量
// printf("%s\n", stringConst);
}
int main() {
TestChar();
return 0;
}
建议:
- 总是使用
const char *来处理字符串字面量,以避免意外修改。 - 当需要修改字符串内容时,使用
char[]数组或动态分配内存。
数组名与数组地址的关系
在 C 语言中,数组名(例如 a)代表数组首元素的地址。形式上,数组名 a 等同于 &a[0],即数组 a 中第一个元素的地址。然而,&a 的含义并非数组变量的地址,而是指向整个数组的指针,这与数组名 a 在语义上有所不同。
- 数组名
a:- 数组名
a在内存中不占用存储空间;它仅代表数组首元素的地址。
- 数组名
- 取地址操作
&a:&a得到的是指向整个数组的指针,而不是数组名a的地址。
- 数组名和地址运算:
- 当使用
a时,它代表数组的首地址。 - 表达式
a + 1实际上表示数组首地址加上一个数组元素的大小,从而指向下一个数组元素。 - 表达式
&a + 1则表示指向整个数组的指针加上一个数组的大小,从而指向下一个数组的起始位置。
- 当使用
- 示例代码:
void TestArrayAddress() {
int a[] = {1, 2, 3, 4, 5};
int *p = a; // p 指向数组的第一个元素
printf("a: %p\n", (void *)a); // 输出数组首地址 0x7ffffcbf0
printf("a + 1: %p\n", (void *)(a + 1)); // 输出下一个元素的地址 0x7ffffcbf4
printf("&a: %p\n", (void *)&a); // 输出数组指针的地址(通常不使用) 0x7ffffcbf0
printf("&a + 1: %p\n", (void *)((char *)&a + sizeof(a))); // 指向下一个数组的起始位置 0x7ffffcc04
}9
注意事项:
&a的使用在 C 语言中并不常见,因为数组的名称本身就是地址。- 在实际编程中,应避免使用
&a,而是直接使用数组名a。
常见的内存操作函数
memcpy() 与 strcpy() 函数
memcpy() 和 strcpy() 都是 C 语言中用于内存复制的函数:
strcpy()函数:strcpy()函数用于复制字符串,它从源字符串的起始位置复制直到遇到空字符'\0'。- 由于字符串以
'\0'结尾,strcpy()不需要指定要复制的字符数量,它会自动停止复制。
memcpy()函数:memcpy()函数用于复制任意类型的内存块,它可以复制指定数量的字节。- 与
strcpy()不同,memcpy()需要明确指定要复制的字节数。
void TestMemcpy() {
char string1[] = "ABCDE";
char *string2 = "FGHIJ";
memcpy(string1, string2, 4); // string2 复制 4 个字节到 string1 中
printf("string1: %s\n", string1); // FGHIE
}
memchr() 与 strchr() 函数
memchr() 和 strchr() 函数都用于查找字符:
strchr()函数:strchr()函数用于在一个字符串中查找第一次出现指定字符的位置。- 它从字符串的开始位置向左到右搜索,直到找到匹配的字符或遇到字符串的结尾(
'\0')。
memchr()函数:memchr()函数用于在一段内存中查找第一个出现指定字符的位置。- 它搜索指定长度的内存块,直到找到匹配的字符或搜索完所有指定的内存。
void TestMemchr() {
// 从字符串中查找
char string1[] = "Hello";
char *temp = memchr(string1, 'l', 5);
printf("%s\n", temp); // llo
// 从数组中查找
int a[] = {0, 1, 2, 3, 4};
char *temp2 = memchr(a, 48, 5); // 48 对应的是 ASCII 码表中的 '0'
printf("%s\n", temp2); // (null)
}
memcmp() 与 strcmp() 函数
strcmp()函数:strcmp()函数用于比较两个字符串。它逐个字符比较,直到发现两个不同的字符或遇到字符串的结束符'\0'。- 如果
left字符在字典序上小于right字符,返回-1;如果大于,则返回1;如果两个字符串相同,则返回0。
memcmp()函数:memcmp()函数用于比较两个内存块。它可以比较任意类型的数据,包括但不限于字符串。- 它逐字节比较,直到比较了指定的字节数,或者发现不同的字节。
- 比较字符串:
- 使用
memcmp()比较字符串时,可以指定要比较的字节数。如果两个字符串在指定的字节范围内相同,memcmp()返回0。
- 使用
- 比较数组:
- 当比较两个数组时,
memcmp()逐字节比较,直到发现不同的字节或比较了指定的字节数。 - 在比较整型数组时,需要注意数组元素的大小。例如,一个
int类型的元素可能占用 4 个字节,因此比较时应该以 4 的倍数为步长。
- 当比较两个数组时,
void TestMemcmp() {
// 比较字符串大小
char *left = "Hello W";
char *right = "Hello C";
printf("%d\n", memcmp(right, left, 7)); // right < left -1
printf("%d\n", memcmp(left, right, 7)); // left > right 1
printf("%d\n", memcmp(left, right, 6)); // left = right 0
// 比较数组大小
int a[] = {2, 2, 0, 4, 5};
int b[] = {2, 2, 3, 4, 5};
int result = memcmp(a, b, 8);
printf("a ? b: %d\n", result); // a ? b: 0
int result2 = memcmp(a, b, 9);
printf("a ? b: %d\n", result2); // a ? b: -1
}
如上述代码所示,a 数组和 b 数组比较前八个字节时,a == b,比较第九个字节时才能发现 a < b。原因在于 memcmp() 函数是一个字节位一个字节位进行数组元素比较的,如下图所示,数组中的第三个元素是从第八个字节位开始存储的(0 为起点)。

memset() 函数
memset() 函数是一个用于内存设置的函数,它可以将指定数量的内存块(字节)的存储值都设置为一个给定的值。
- 函数定义:
memset()函数接受三个参数:要设置的内存块的指针、要设置的值以及要设置的字节数。
- 函数行为:
- 函数从给定的内存地址开始,将连续的指定数量的字节设置为第二个参数指定的值。
void TestMemset() {
char *a = malloc(5); // 请求分配 5 个字节
for (int i = 0; i < 5; ++i) {
printf("%d, ", a[i]); // -51, -51, -51, -51, -51,
}
memset(a, 0, 5); // 将 5 个字节的值设置为 0
printf("\n");
for (int i = 0; i < 5; ++i) {
printf("%d, ", a[i]); // 0, 0, 0, 0, 0,
}
free(a);
}
memmove() 函数
memmove() 函数用于复制内存块,它在功能上与 memcpy() 函数相似,但适用于源内存区域和目标内存区域重叠的情况。
- 函数定义:
memmove()函数接受三个参数:目标内存地址、源内存地址和要复制的字节数。
- 函数行为:
- 该函数首先将源内存区域的内容复制到一个临时缓冲区,然后再将这些内容复制到目标内存区域,从而避免了由于内存重叠导致的数据破坏。
- 注意事项:
- 当源和目标内存区域重叠时,使用
memmove()可以安全地复制内存,而不必担心数据丢失或损坏。 memcpy()在非重叠的情况下更高效,但在重叠情况下可能导致未正确复制原始数据。
- 当源和目标内存区域重叠时,使用
void TestMemmove() {
char str[] = "memmove can be very useful......";
memmove(str + 20, str + 15, 11);
puts(str); // memmove can be very very useful.
char str2[] = "memmove can be very useful......";
memcpy(str2 + 20, str2 + 15, 11);
puts(str2); // memmove can be very very useful.
}

如上图所示,当第一个变量(userful…..)和第二个变量(very useful)的内存块有重叠时,memmove() 函数可以将第二个变量的值先放入缓冲区,然后再对第一个变量的值进行覆盖。这样做的好处是,以第 20 位的 u 为例,防止 u 没有复制到 25 位时,值就被改写了。这里的矛盾在于,第 15 位的 v 要复制到第 20 位 u,第 20 位 u 要复制到第 25 位 i,有个前后顺序的问题,应该先将 20 位的 u 复制到 25 位的 i 上,再把 15 位的 v 复制到 20 位 u 上。
C99 的 restrict
在 C 语言中,restrict 是一个关键字,用于向编译器提供有关指针参数的额外信息。使用 restrict 可以提高某些操作的性能,因为它允许编译器进行特定的优化。
- 关键字定义:
restrict表明使用该关键字修饰的指针是唯一的,即它是指向其指定内存区域的唯一指针。
- 使用场景:
restrict通常用于函数参数中,指示编译器该参数指向的内存区域不会被函数中的其他指针参数所引用。
- 性能优化:
- 当编译器知道没有两个指针指向相同的内存区域时,它可以执行某些优化,例如消除不必要的同步操作或改进缓存使用。
// \Cygwin\usr\include\string.h
// 31:1
void * memcpy (void *__restrict, const void *__restrict, size_t);
// 32:1
void * memmove (void *, const void *, size_t);
memmove() 函数参数中不存在 __restrict__,说明该函数允许实参内存重叠, memcpy() 函数存在该关键字,说明不允许实参内存重叠。当函数参数数量为 1 时,不需要考虑此关键字,一个参数不存在内存重叠问题。
C11 安全版本的函数
安全函数,如 strcpy_s() 和 strcat_s(),是 strcpy() 和 strcat() 的安全替代品。它们在功能上与原函数相似,但在函数原型上有所改变。
安全函数通常接受额外的参数,用于指定目标字符串的缓冲区大小。例如,strcpy_s(char *dest, rsize_t destsz, const char *src),其中 rsize_t 是大小的类型,destsz 是目标缓冲区的大小。
安全函数的返回值是 error_t 类型,而不是原函数的 char* 类型。error_t 通常是一个整型,用于表示函数执行成功或失败的状态。
// \Windows Kits\10\Include\10.0.22621.0\ucrt\string.h
// 130:1
__DEFINE_CPP_OVERLOAD_STANDARD_FUNC_0_1(
char*, __RETURN_POLICY_DST, __EMPTY_DECLSPEC, strcpy,
_Out_writes_z_(_String_length_(_Source) + 1), char, _Destination,
_In_z_ char const*, _Source
);
// 31:5
_Check_return_wat_
_ACRTIMP errno_t __cdecl strcpy_s(
_Out_writes_z_(_SizeInBytes) char* _Destination,
_In_ rsize_t _SizeInBytes,
_In_z_ char const* _Source
);
// 91:5
__DEFINE_CPP_OVERLOAD_STANDARD_FUNC_0_1(
char*, __RETURN_POLICY_DST, __EMPTY_DECLSPEC, strcat,
_Inout_updates_z_(_String_length_(_Destination) + _String_length_(_Source) + 1), char, _Destination,
_In_z_ char const*, _Source
);
// 38.5
_Check_return_wat_
_ACRTIMP errno_t __cdecl strcat_s(
_Inout_updates_z_(_SizeInBytes) char* _Destination,
_In_ rsize_t _SizeInBytes,
_In_z_ char const* _Source
);
error_t 本质上是 int 类型,不同的数值代表不同的错误类型。如果返回值为 0,表示函数执行成功;如果返回非 0 值,则表示函数执行过程中遇到了错误。
错误码可以用来确定错误的种类,并据此进行相应的错误处理。可以利用 perror 查看错误种类。
void TestPerror() {
char des[2];
// 第一个参数为目标字符串,第二个参数为目标字符串的容量,第三个参数是待拷贝的字符串
int error_no = strcpy_s(des, 2, "Hello");
printf("error: %d\n", error_no);
if (error_no) {
// 程序运行不成功,error_no 非 0
perror("strcpy_s returns");
}
}

可以发现 error 值为 34,说明程序运行失败,错误原因是 result too large,即待拷贝的字符串过大。