
标准模版库
Standard Template Library(STL),是一种高效且功能强大的 C++ 程序库,被纳入 C++ 标准库中,是 ANSI/ISO C++ 规范中最新且具有创新性的一部分。它包含了计算机科学中常用的基本数据结构和算法,为 C++ 开发者提供了一个可扩展的框架,体现了软件复用性。
STL 采用了泛型编程模式,与面向对象编程不同,它允许编写适用于多种数据类型的通用代码。这种模式通过抽象化数据类型,使用泛型代替具体类型,来实现代码的通用性。
STL 虽然复杂,但可以概括为六个主要组件:容器、迭代器、算法、适配器、函数对象和空间配置器。
- 容器:提供数据结构,分为序列式(如 vector、list)、关联式(如 set、map)和无序关联式(如 unordered_set、unordered_map)。
-
迭代器:一种抽象数据类型,用于访问容器元素,类似于 C 语言中的指针,被称为泛型指针。
-
算法:提供对容器元素操作的函数模板,包括查找、排序、合并、去重、集合操作、求极值和数值计算等。
-
适配器:用于修饰容器、函数或迭代器接口,使一种事物的行为类似于另一种事物,类似于转接器。
-
函数对象:也称仿函数,可作为算法策略,是封装了函数或函数指针的对象,可以像函数一样调用,也可以像对象一样被赋值或传递。
-
空间配置器:负责内存的分配与释放。
序列式容器
序列式容器包括:静态数组 array、动态数组 vector、双端队列 deque、单链表 forward_list、双链表 list。下面主要讲解个 vector、deque、list 的使用。
概览



初始化容器对象
对于序列式容器而言,初始化的方式一般会有五种。
// 1. 初始为空
vector<int> vNum1;
deque<int> dNum1;
list<int> lNum1;
// 2. 初始为多个相同的值
vector<int> vNum2(10, 1);
deque<int> dNum2(10, 1);
list<int> lNum2(10, 1);
// 3. 使用迭代器范围
int arr[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
vector<int> vNum3(arr, arr + 10); // 左闭右开
deque<int> dNum3(arr, arr + 10);
list<int> lNum3(arr, arr + 10);
// 4. 使用大括号
vector<int> vNum4 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
deque<int> dNum4 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
list<int> lNum4 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// 5. 拷贝构造 / 移动构造
vector<int> vNum5 = {1, 2, 3, 4};
vector<int> vNum6(vNum5);
vector<int> vNum7(std::move(vNum6));
deque<int> dNum5 = {1, 2, 3, 4};
deque<int> dNum6(dNum5);
deque<int> dNum7(std::move(dNum6));
list<int> lNum5 = {1, 2, 3, 4};
list<int> lNum6(lNum5);
list<int> lNum7(std::move(lNum6));






遍历容器元素
// 1. 使用下标进行遍历(容器必须支持下标访问)
for (size_t idx = 0; idx < vNum.size(); ++idx) {
cout << vNum[idx] << " " << endl;
}
cout << endl;
for (size_t idx = 0; idx < dNum.size(); ++idx) {
cout << dNum[idx] << " " << endl;
}
cout << endl;
/*for (size_t idx = 0; idx < lNum.size(); ++idx) {
cout << lNum[idx] << " " << endl;
// Type 'list<int>' does not provide a subscript operator
}
cout << endl;*/
// 2. 使用未初始化的迭代器方式进行遍历
vector<int>::iterator it;
for (it = vNum.begin(); it != vNum.end(); ++it) {
cout << *it << " ";
}
cout << endl;
// 3, 使用已初始化的迭代器方式进行遍历
auto it2 = vNum.begin();
for (; it2 != vNum.end(); ++it2) {
cout << *it2 << " ";
}
cout << endl;
// 4. 增强 for 循环的形式
for (auto &elem : vNum) {
cout << elem << " ";
}
cout << endl;
三种序列式容器 vector、deque、list 都支持使用迭代器、增强 for 循环的形式进行遍历,同时 vector 与 deque 还支持使用下标进行遍历,但是 list 没有重载下标访问运算符,所以不支持使用下标进行遍历。
在尾部进行插入与删除






vNum.push_back(11);
vNum.push_back(22);
for (auto &elem : vNum) {
cout << elem << " ";
}
cout << endl;
vNum.pop_back();
for (auto &elem : vNum) {
cout << elem << " ";
}
三种序列式容器 vector、deque、list 在尾部进行插入与删除是完全一致的。
在头部进行插入与删除




vNum.push_front(100);
vNum.push_front(200);
vNum.pop_front(100);
序列式容器 deque 与 list 可以在头部进行插入与删除,但是 vector 不能在头部进行插入与删除。
vector 的原理

vector 不支持在头部进行插入和删除的原因在于其内部实现。vector 是一个动态数组,它在内存中是连续存储的。这种连续存储的特性使得在 vector 的末尾进行插入和删除操作非常高效,因为只需要改变元素的位置,不需要重新分配整个数组的内存。
然而,如果在 vector 的头部进行插入或删除操作,情况就完全不同了。由于所有元素都是连续存储的,插入或删除头部的元素需要移动整个 vector 中的所有其他元素以保持连续性。具体来说,插入操作需要将所有现有元素向后移动一个位置,为新元素腾出空间;删除操作则需要将所有后续元素向前移动一个位置,填补被删除元素留下的空位。这样的操作对于拥有大量元素的 vector 来说是非常低效的,因为它需要移动 O(N) 个元素,其中 N 是 vector 中元素的数量。
vector 的底层实现通常依赖于动态分配的连续内存块来存储其元素。在 C++ 标准库中,vector 的实现细节是容器提供者定义的,通常遵循一定的模式。
vector 在创建时会请求一定量的内存来存储其元素。随着元素的添加,当内存不足以容纳更多元素时,vector 会重新分配更大的内存块,并将现有元素复制到新的内存位置。
三个指针:
_M_start:指向vector中第一个元素的指针。_M_finish:指向vector中最后一个元素之后的位置的指针,即当前有效数据的末尾。_M_end_of_storage:指向vector分配的内存块的末尾的下一个位置的指针,即分配的内存的边界。
这三个指针使得 vector 能够管理其内部的内存,并提供快速的随机访问能力。_M_start 和 _M_finish 之间的内存区域用于存储 vector 的元素,而 _M_finish 和 _M_end_of_storage 之间的内存区域是未使用的,可以用于以后的扩展。


要获取 vector 中第一个元素的首地址,不能直接对 vector 对象取地址,因为 vector 对象包含了除了存储元素之外的其他数据(如上述的三个指针、分配的内存大小等元数据)。正确的方式是使用 vector 提供的 data() 或 begin() 成员函数。
int* first_element_address = vNum.data(); // 获取第一个元素的地址
// 或者
int* first_element_address = &vNum[0]; // 通过下标访问第一个元素的地址
// 或者
int* first_element_address = vNum.begin(); // 获取指向第一个元素的迭代器,然后取地址
deque 的原理

deque(双端队列)在 C++标准模板库(STL)中的实现通常采用一个或多个固定大小的数组片段,并通过一个控制器来管理这些片段。这种设计使得 deque 在头部和尾部进行插入和删除操作时非常高效,因为这些操作不需要移动其他元素。
deque 由多个固定大小的数组片段组成,这些片段内部的元素是连续存储的,但片段之间在内存中是不连续的。

deque 使用一个控制器(通常是一个二级指针, _M_map)来管理这些片段。这个控制器存储了指向各个片段的指针,以及一些其他管理信息,如片段的大小和使用情况。
deque 的迭代器不是一个简单的指针类型,而是一个类类型。这是因为 deque 需要在不同的片段之间进行导航,并且需要处理片段的动态分配和释放。迭代器通常包含两个指针,一个指向当前片段,另一个指向片段内的元素位置。
deque 在需要时动态地分配和释放片段,这使得它能够灵活地处理大小变化。当 deque 增长时,它可能会分配新的片段,并在必要时将元素从一个片段移动到另一个片段。
由于 deque 的片段是固定大小的,因此在片段内部进行插入和删除操作时,通常只需要处理少量的元素移动。但是,当元素需要从一个片段移动到另一个片段时,可能会涉及到更多的元素移动,这可能会影响性能。

list 的原理

list 是一个双向链表的容器,它提供了一种灵活且高效的元素插入和删除操作。
list 的底层实现基于节点,每个节点包含一个元素以及指向前一个节点和后一个节点的指针。这种结构使得在链表的任何位置进行插入和删除操作的时间复杂度都是 O(1),因为不需要像在数组中那样移动其他元素。
由于需要维护额外的指针,每个节点的内存开销比数组中的元素要大。此外,由于节点在内存中不一定是连续存储的,所以 list 不支持随机访问操作,这使得它在需要频繁随机访问元素的场景下不如 vector 高效。
list 的迭代器是双向的,允许向前和向后遍历,但不支持像 vector 那样的快速随机访问迭代器。这种设计使得 list 在处理需要频繁插入和删除元素的场景时非常有用,尤其是在元素数量变化较大的情况下。
在容器的任意位置插入



auto it = vNum.begin();
it += 2 // ERROR
++it;
++it;
// 1. 在 it 的前面插入一个元素
vNum.insert(it, 123);
// 2. 在 it 的前面插入 count 个相同的元素
vNum.insert(it, 4, 11);
// 3. 在 it 的前面插入迭代器范围的元素
vector<int> vec = {111, 333, 555, 222};
vNum.insert(it, vec.begin(), vec.end());
// 4. 在 it 的前面加入大括号范围的元素
vNum.insert(it, {200, 500, 700, 300});
vector、deque 和 list 这三种序列式容器都提供了丰富的 insert 操作,允许在容器的任意位置插入单个元素、一系列相同元素、从迭代器指定范围的元素,以及使用大括号初始化的元素。
list 作为一个双向链表,其 insert 操作非常高效,因为它不要求元素在内存中连续存储,因此在任何位置插入元素都不会导致其他元素的移动,迭代器也不会失效。
vector 由于其内部实现为一段连续的内存空间,所以在中间位置插入元素时,需要将插入点之后的所有元素向后移动,以腾出空间,这会导致插入点之后的所有迭代器失效。此外,如果插入操作导致 vector 的容量不足,它可能需要进行内存重新分配,这时所有迭代器都会失效,因为元素被复制到了新的内存位置。
deque 也可能因为插入操作而需要扩容,尤其是在插入大量元素时,这同样可能导致迭代器失效。即使没有发生扩容,deque 在中间位置的插入操作也会导致插入点之后的所有迭代器失效,因为它们指向的元素位置发生了变化。因此,在处理大量数据或频繁的插入操作时,选择正确的容器类型对于程序的性能和稳定性至关重要。
vector 的迭代器失效
以 vector 为例,如果使用 insert 插入元素,而每次插入元素的个数不确定,可能剩余空间不足以存放插 入元素的个数,那么 insert 在插入的时候底层就可能导致扩容,从而导致迭代器还指向老的空间,继续使用该迭代器会出现迭代器失效的问题。
vector<int> vNum = {1, 2, 3, 4, 5, 6, 7, 8, 9};
cout << "vNum.size() = " << vNum.size() << endl; // 9
cout << "vNum.capacity() = " << vNum.capacity() << endl; // 9
cout << endl << "在容器尾部进行插入: " << endl;
vNum.push_back(10);
vNum.push_back(11);
cout << "vNum.size() = " << vNum.size() << endl; // 11
cout << "vNum.capacity() = " << vNum.capacity() << endl; // 18
cout << endl << "在容器vector中间进行插入: " << endl;
auto it = vNum.begin();
++it;
++it;
vNum.insert(it, 22);
cout << "*it = " << *it << endl;
cout << "vNum.size() = " << vNum.size() << endl; // 12
cout << "vNum.capacity() = " << vNum.capacity() << endl; // 18
vNum.insert(it, 7, 100); // 因为插入个数不确定,有可能底层已经发生了扩容
cout << "*it = " << *it << endl;
cout << "vNum.size() = " << vNum.size() << endl; // 19
cout << "vNum.capacity() = " << vNum.capacity() << endl; // 24
// 正确办法是重置迭代器的位置
vector<int> vec1{51, 52, 53, 56, 57, 59};
vNum.insert(it, vec1.begin(), vec1.end());// 继续使用该迭代器就会出现问题(内存错误)
cout << "*it = " << *it << endl;
cout << "vNum.size() = " << vNum.size() << endl;
cout << "vNum.capacity() = " << vNum.capacity() << endl;
// 解决方案:每次在插入元素的时候,可以将迭代器的位置进行重置更新
// 避免因为底层扩容,迭代器还指向老的空间而出现问题
vector<int> vec{51, 52, 53, 56, 57, 59};
it = vNum.begin(); // 重新置位
++it;
++it;
vNum.insert(it, vec.begin(), vec.end()); // 继续使用该迭代器就会出现问题(内存错误)
cout << "*it = " << *it << endl;
cout << "vNum.size() = " << vNum.size() << endl;
cout << "vNum.capacity() = " << vNum.capacity() << endl;
对于 vector 的 insert 操作,确实存在容量不足时需要扩容的情况。vector 的扩容策略通常是为了平衡内存使用和性能,其扩容机制比简单的两倍扩容要复杂一些。
- 当剩余容量足够:如果
vector的当前容量n减去当前大小m(即n - m)大于或等于要插入的元素个数t,那么vector不需要扩容,可以直接在指定位置插入元素。 - 当剩余容量不足但不足以容纳所有插入元素:如果剩余容量不足以容纳所有要插入的元素,但
t小于当前大小m,那么vector会选将容量增加到2m,这样可以确保有足够的空间来容纳所有元素,同时保持扩容的幅度不会过大。 - 当需要插入的元素个数接近当前容量:如果
t大于m但小于n,或者t接近n,那么vector会选择一个更大的扩容策略,比如将新容量设置为t + m,这样可以确保有足够的空间来容纳所有新插入的元素,同时减少未来可能的连续扩容操作。 - 当需要插入的元素个数远大于当前容量:如果
t远大于当前容量n,那么vector会将新容量设置为至少t + m,这样可以确保有足够的空间来容纳所有新插入的元素,同时考虑到未来可能的插入操作。
在容器的任意位置删除元素



序列式容器如 vector、deque 和 list 在删除元素时对迭代器的影响各不相同,这主要是由于它们的内部数据结构和设计目的不同。
对于 vector 而言,删除操作会导致删除迭代器之后的所有元素前移,这会使得所有指向被删除元素之后位置的迭代器失效。失效的原因是尽管迭代器的位置没有改变,但由于元素的移动,迭代器不再指向删除操作之前的元素。vector 的这种特性意味着在进行删除操作时,需要特别小心,尤其是在循环中使用迭代器时,因为每次删除都可能导致后续迭代器失效。
deque 的删除操作则更为复杂。deque 由多个固定大小的数组片段组成,这些片段在内存中不一定是连续的。deque 的 erase 操作会根据删除位置与容器大小的一半来决定是挪动前一半还是后一半的元素,以此来尽量减少元素挪动的次数。这种设计使得 deque 在两端进行删除操作时非常高效,但如果在中间位置进行删除,可能需要移动多个片段中的元素,这可能导致更多的迭代器失效。
相比之下,list 的删除操作相对简单。由于 list 是一个双向链表,每个元素都包含指向前一个和后一个元素的指针,因此删除操作只需要改变被删除元素相邻元素的指针,而不需要移动其他元素。这使得 list 在任何位置进行删除操作都非常高效,并且只会导致指向被删除元素的迭代器失效,而不会影响其他迭代器。
// 题意:删除 vector 中所有值为 4 的元素。
vector<int> vec = {1, 3, 5, 4, 4, 4, 4, 7, 8, 4, 9};
for (auto it = vec.begin(); it != vec.end(); ++it) {
if (4 == *it) {
vec.erase(it);
}
}
// 发现删除后有些 4 没有删除掉,可以推测出是什么原因吗?是哪些 4 没有删除呢?
// 正确解法:
for (auto it = vec.begin(); it != vec.end();) {
if (4 == *it) {
vec.erase(it);
} else {
++it;
}
}
return 0;
元素的清空





三种序列式容器 vector、deque、list 都有清空操作 clear 函数以及记录元素个数的函数 size。对于 vector 与 deque 而言,还有回收多余空间的函数 shrink_to_fit 函数,特别的对于 vector 还有记录容量的函数 capacity。
改变元素个数



三种序列式容器 vector、deque、list 都支持 resize 操作(改变元素的个数),如果 resize 之后的元素个数比之前要多,那么多的元素会使用默认值;那么如果 resize 之后的元素的个数比之前要少,那么多余的会被删除。
交换两个同类型容器中的内容



三种序列式容器 vector、deque、list 都支持 swap 函数,交换两个容器的内容。
下标访问




对于 vector 与 deque 而言,都支持下标或者 at 函数进行随机访问,但是下标没有范围检查,容易越界,有缺陷。
at 会有范围检查,越界会有异常抛出,所以更加安全。
emplace 系列函数




vector<Point> vec;
Point pt(1, 2);
cout << endl << "-----" << endl;
vec.push_back(pt); // 没有区别
vec.emplace_back(pt);
cout << endl << "++++++++" << endl;
vec.push_back(Point(1, 2)); // 没有区别
vec.emplace_back(Point(1, 2));
cout << endl << endl;
vec.push_back(Point(1, 2)); // 多执行一次拷贝构造
vec.emplace_back(1, 2);
list 的特殊操作
链表的逆置 reverse 函数

list<int> list = {8, 7, 5, 9, 0, 1, 3, 2, 6, 4};
cout << "初始:" << list << '\n';
list.sort();
cout << "升序:" << list << '\n';
list.reverse();
cout << "降序:" << list << '\n';
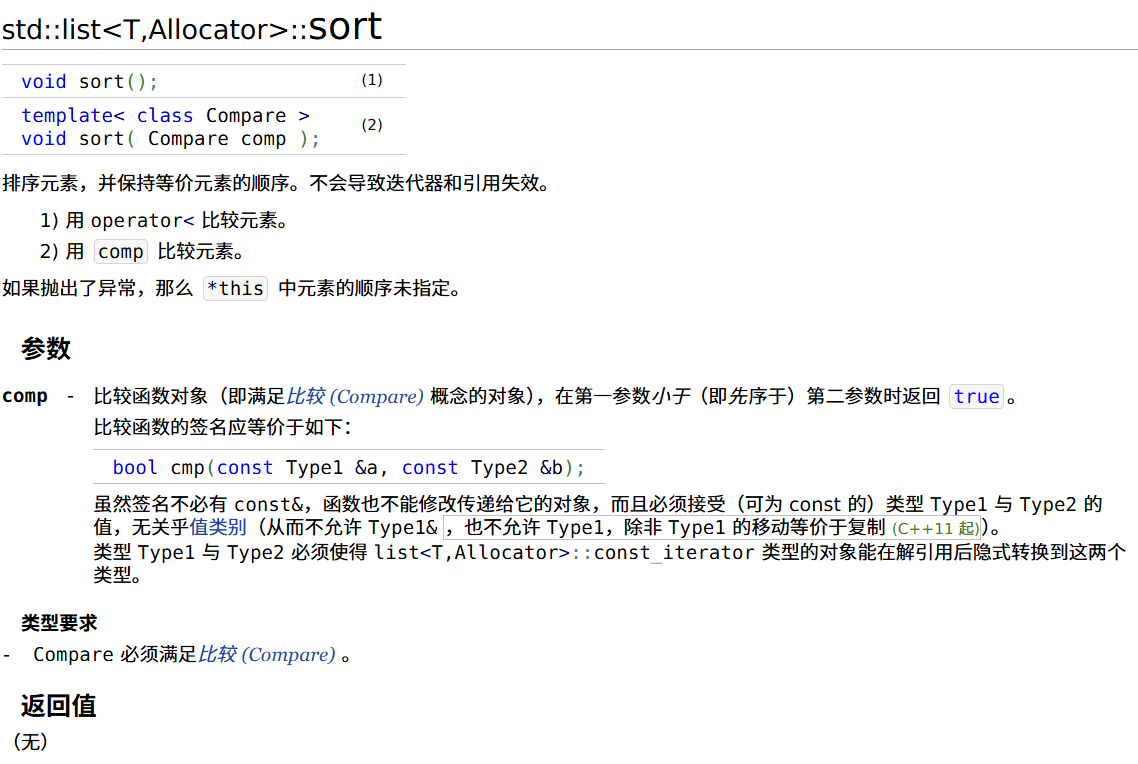
链表的排序 sort 函数
struct CompareList {
bool operator()(const int &lhs, const int &rhs) const {
cout << "struct CompareList" << endl;
return lhs < rhs;
}
};
int main() {
list<int> list{8, 7, 5, 9, 0, 1, 3, 2, 6, 4};
cout << "初始:" << list << '\n';
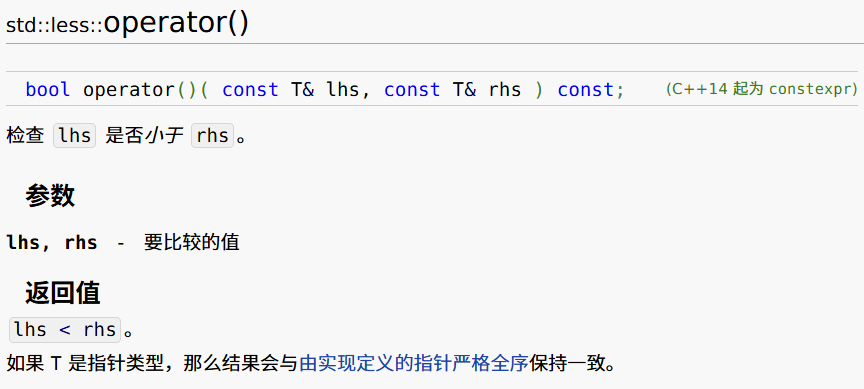
list.sort(less<>());
cout << "升序:" << list << '\n';
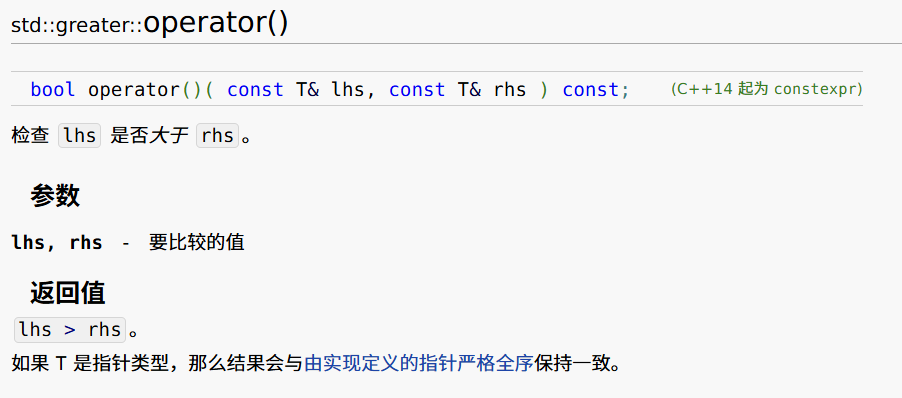
list.sort(greater<>());
cout << "降序:" << list << '\n';
list.sort(CompareList());
cout << "自定义排序:" << list << '\n';
}
去除连续重复元素 unique
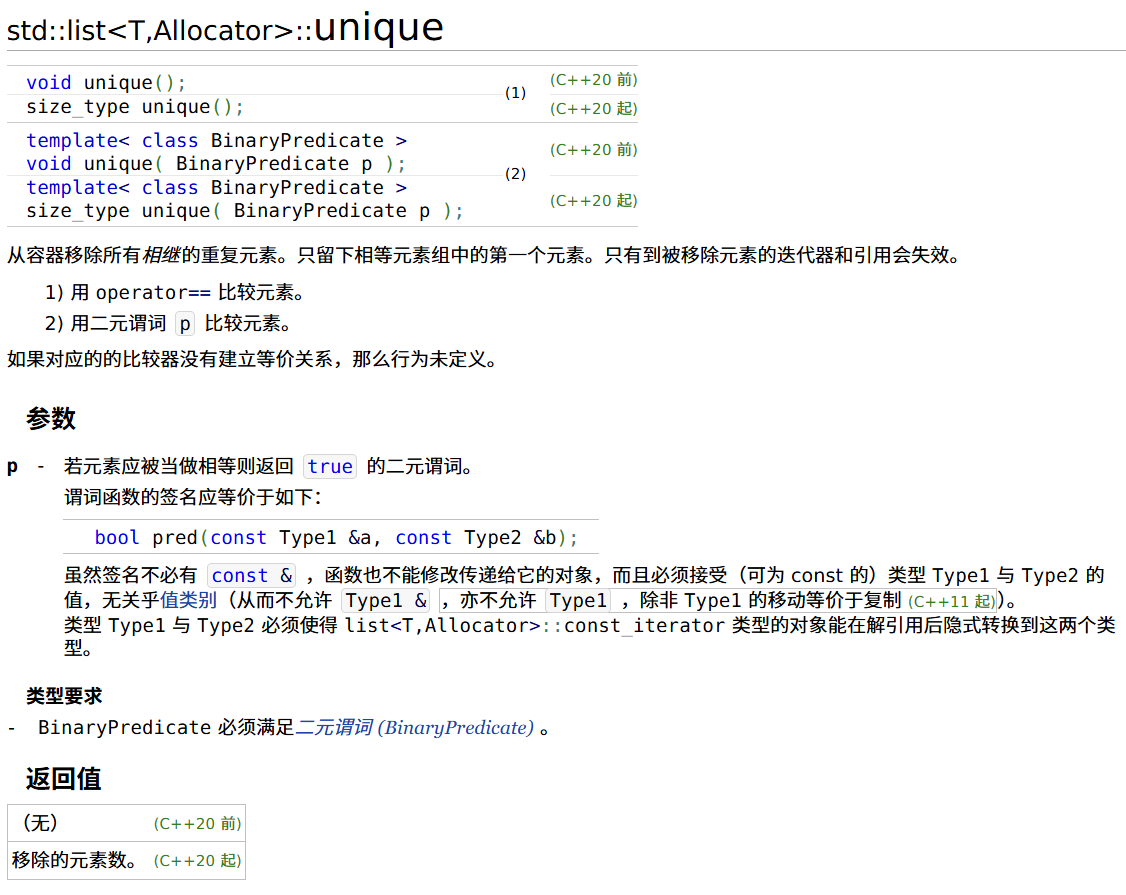
list<int> c = {1, 2, 2, 3, 3, 2, 1, 1, 2};
cout << "unique() 前:" << c;
const auto count1 = c.unique();
cout << "unique() 后:" << c
<< "移除了 " << count1 << " 个元素\n";
c = {1, 2, 12, 23, 3, 2, 51, 1, 2, 2};
cout << "\nunique(pred) 前:" << c;
const auto count2 = c.unique([mod = 10](int x, int y) {
return (x % mod) == (y % mod);
});
cout << "unique(pred) 后:" << c
<< "移除了 " << count2 << " 个元素\n";
两个链表的合并 merge
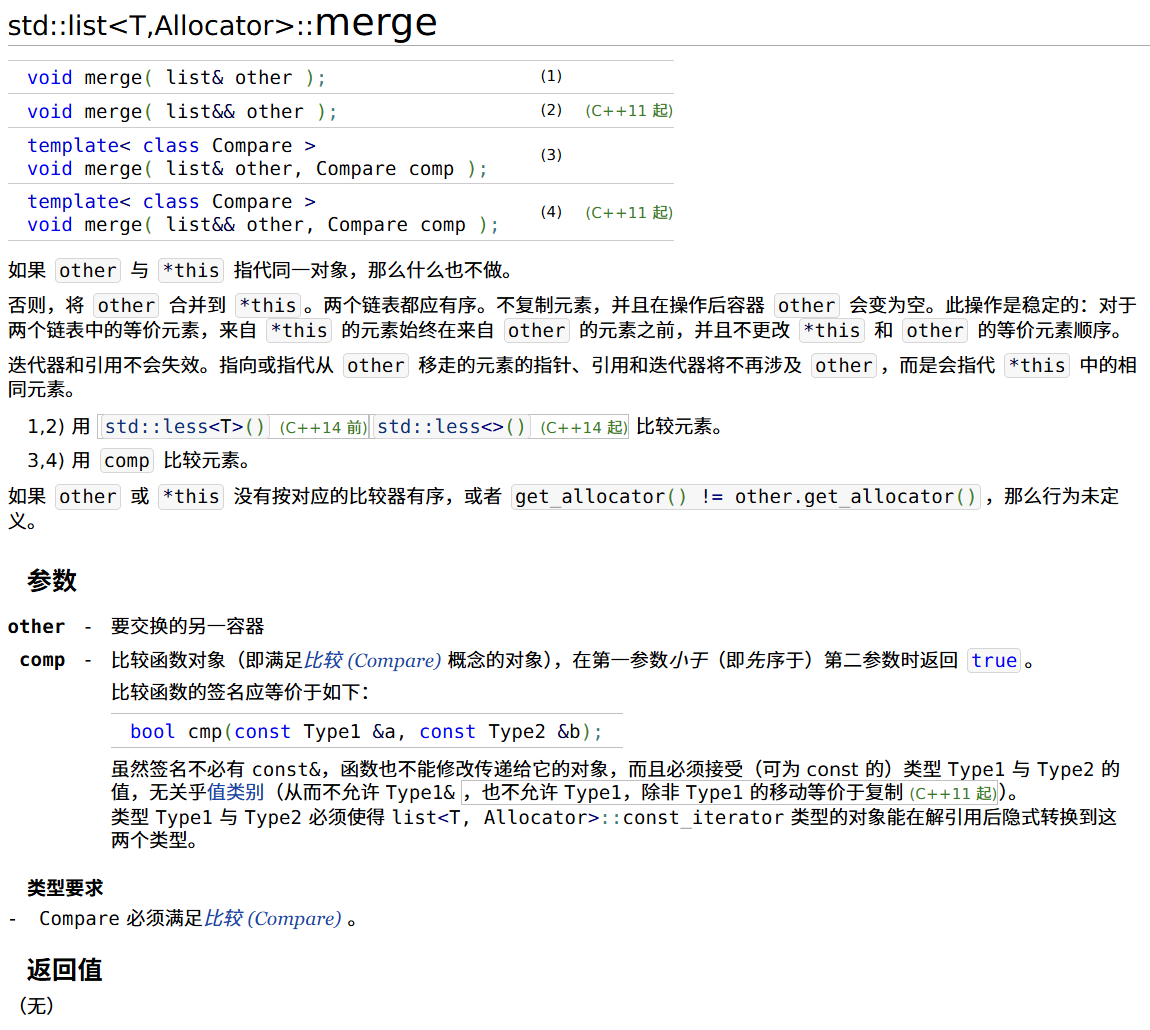
list<int> list1 = {5, 9, 1, 3, 3};
list<int> list2 = {8, 7, 2, 3, 4, 4};
list1.sort();
list2.sort();
cout << "list1:" << list1 << '\n';
cout << "list2:" << list2 << '\n';
list1.merge(list2);
cout << "合并后:" << list1 << '\n';
两个链表在进行 merge 之前一定都要先按照从小到大进行排序,这样 merge 之后,最终的链表才是真正有序的。
链表的 splice 操作
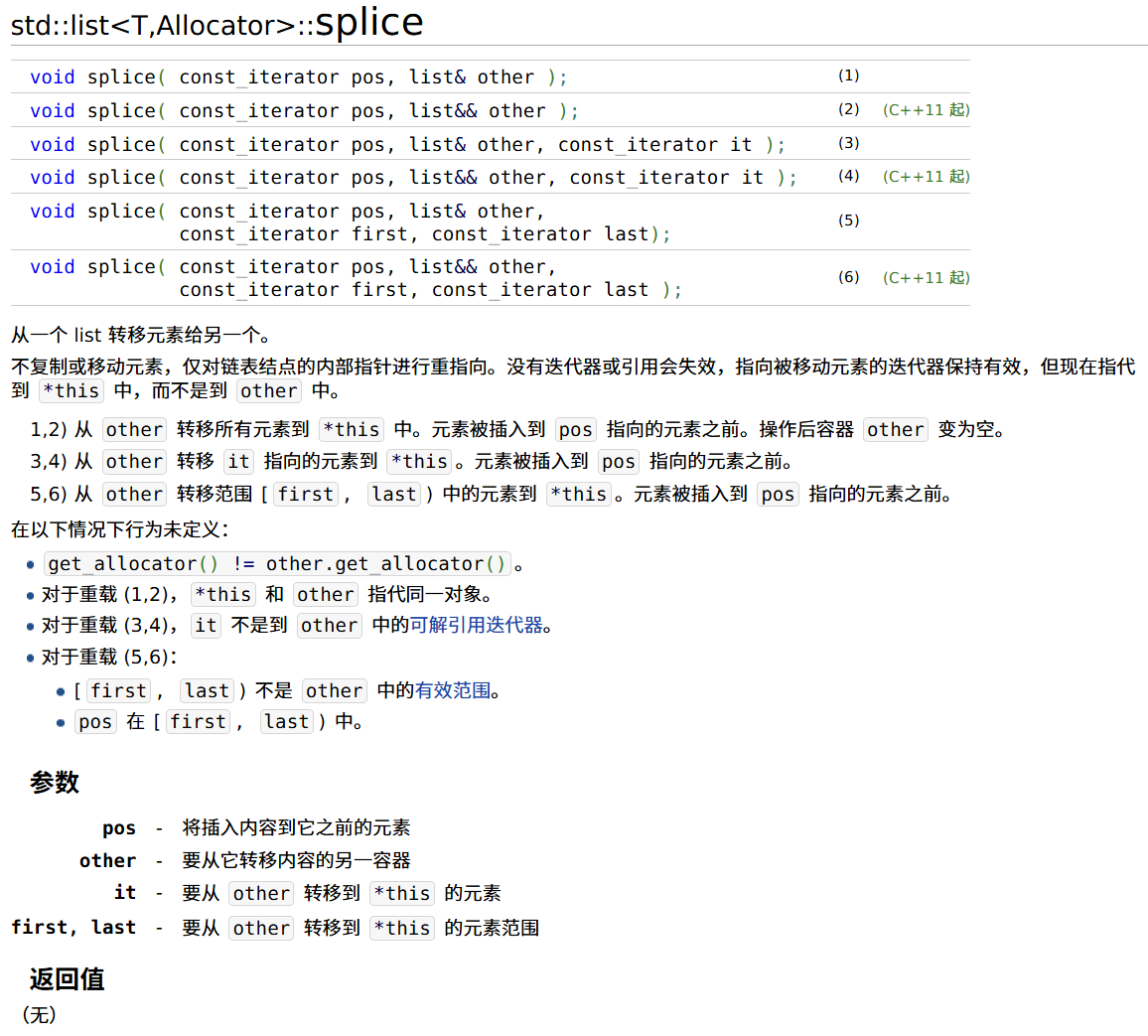
list<int> list1{1, 2, 3, 4, 5};
list<int> list2{10, 20, 30, 40, 50};
auto it = list1.begin();
advance(it, 2);
list1.splice(it, list2);
cout << "list1:" << list1 << '\n';
// list1: 1 2 10 20 30 40 50 3 4 5
cout << "list2:" << list2 << '\n';
// list2:
list2.splice(list2.begin(), list1, it, list1.end());
cout << "list1:" << list1 << '\n';
// list1: 1 2 10 20 30 40 50
cout << "list2:" << list2 << '\n';
// list2: 3 4 5