
哈希的相关概念
哈希(Hash)是一个数学概念,而哈希表(Hash Table)是一种基于哈希的数据结构。 这两个概念虽然密切相关,但它们在本质上是不同的。哈希表是哈希概念的一种应用,但不应将两者混淆。
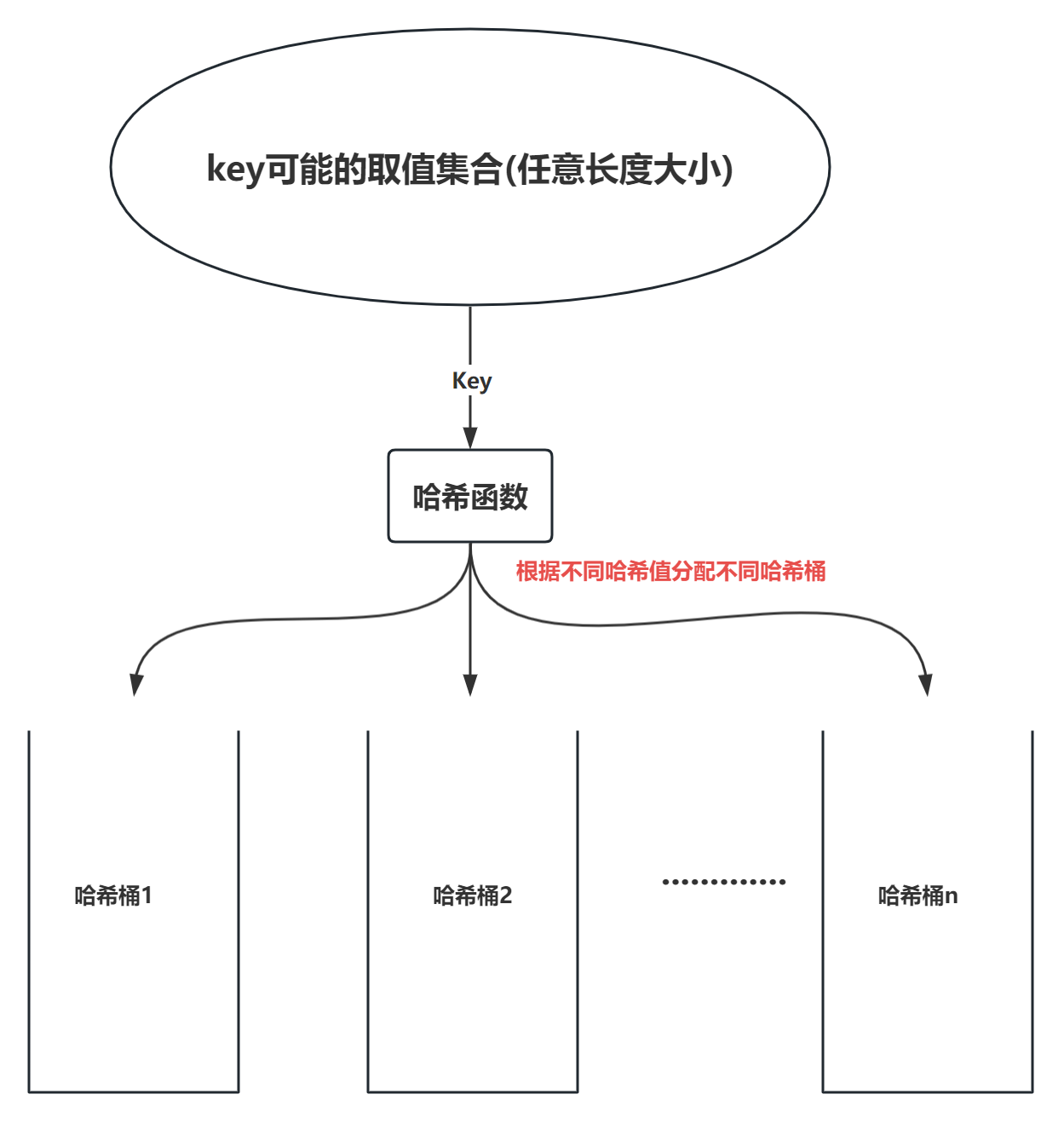
哈希映射 是一种特殊的转换过程,它将任意大小的输入(定义域)转换成固定长度的输出(值域)。这个过程的本质是将无限的输入空间映射到有限的输出空间。
- 定义域:是无限的,可以是任何大小的数据。
- 值域:是固定长度的,通常表现为整数或字符串。
哈希值 是通过哈希过程得到的固定长度的输出,它是哈希表中存储数据的关键。
哈希函数,也称为哈希算法或哈希方法,是实现哈希映射的核心,它定义了如何将无限的输入数据转换成有限的输出数据。
哈希和哈希函数的特点:
- 确定性:对于给定的输入和哈希函数,每次调用都应该产生相同的输出。这意味着,相同的输入不会映射到多个输出上。
- 非唯一性:不同的输入可能会映射到相同的输出上,这种情况称为“哈希冲突”。虽然可以通过设计更优的哈希函数或采用其他技术来减少哈希冲突的发生,但理论上无法完全避免。

哈希表的相关概念
哈希表 是一种高效的数据结构,专门用于存储和检索键值对(key-value pairs)。在哈希表中,每个键(key)都是唯一的,作为数据项的标识符,而值(value)则与键相关联。
- 键的唯一性:哈希表中的键必须是唯一的,它们作为数据项的索引,用于快速地存储和检索数据。
- 键与值的关系:键是哈希表中存储数据的关键,而值则与键相关联。在某些哈希表的实现中,值可能不是必需的。
- 存储机制:哈希表的存储过程通常包括以下步骤:
- 首先,计算键的哈希值。
- 然后,根据哈希值确定键值对在哈希表中的存储位置。
- 哈希冲突的处理:由于哈希冲突的存在,可能需要在哈希表的同一位置存储多个键值对。为了解决这个问题,哈希表的基本存储单元——通常称为“哈希桶”(hash bucket),被设计为能够存储多个元素。
- 哈希桶的作用:哈希桶是哈希表中用于存储多个键值对的基本单元。当哈希表需要存储一个新的键值对时,会根据键的哈希值来决定该键值对应该存储在哪个哈希桶中。
哈希表由多个哈希桶组成,这些桶共同构成了数据结构的基础。每当哈希表需要存储一个新的键值对,就会通过计算键的哈希值来确定其在哈希表中的存储位置。
哈希表的抽象理论模型
实现哈希表需要解决选择哈希函数和实现哈希桶的问题。
选择哈希函数
选择哈希函数的要点:
- 性能和效率:哈希表作为频繁操作的容器,对哈希函数的第一个要求是高效的执行速度。哈希函数不应成为哈希表性能的瓶颈。
- 减少哈希冲突:理想的哈希函数应尽量减少冲突,将输入均匀地分布到不同的哈希桶中,从而提升哈希表的整体性能。
- 均匀分布:哈希函数应确保输入数据在哈希表中的分布尽可能均匀,避免大量元素映射到同一个哈希桶,这有助于减少查找时间。
推荐使用哈希函数 MurmurHash32,这是一种输出 32 位无符号整数结果的哈希函数,适合用于实现哈希表。
/* murmur_hash32 */
static uint32_t hash(const void* key, int len, uint32_t seed) {
const uint32_t m = 0x5bd1e995;
const int r = 24;
uint32_t h = seed ^ len;
const unsigned char* data = (const unsigned char*)key;
while (len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
switch (len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0];
h *= m;
};
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return h;
}
使用 MurmurHash32 时的注意事项:
- 键的表示:当键是指针类型时,应将其视为指向键元素内存块的指针。如果键是字符数组或字符串类型,应使用
char*类型,而不是char**。 - 通用指针类型:使用
void*通用指针类型时,需要区分其在不同上下文中的含义。例如,在某些函数中,void*可能表示指向特定内存块的指针。 - 长度参数:
len参数表示键元素内存块的长度。例如,如果键是整数类型,则长度为sizeof(int);如果键是字符串,则长度为strlen(key)。 - 种子值(seed):种子值用于增加哈希计算过程中的随机性,通常取当前时间的时间戳。在同一个哈希表的一次程序执行期间,种子值通常不需要多次改变。
设计哈希桶
设计哈希桶以解决哈希冲突的方法:
- 开放寻址法:
- 这种方法将数组视为哈希表,每个数组元素作为哈希桶。
- 解决哈希冲突的策略包括线性探测法、平方探测法和再哈希法等。
- 尽管理论上可行,但实现起来可能较为复杂,特别是在删除操作和动态数组扩容时。
- 这种方法更适合于小数据集,且主要进行访问或添加操作,几乎不涉及删除的场景。
- 拉链法:
- 这是目前主流的解决方案,通过结合数组和单链表来实现哈希桶。
- 每个数组元素指向一个单链表,所有映射到同一个哈希值的键值对都存储在这个链表中。
- 这种方法在 Java、C++等编程语言的哈希表实现中被广泛采用。
开放寻址法虽然理论上简单,但在实际应用中可能面临实现上的挑战,特别是在需要频繁删除操作或动态扩容的场景。
拉链法则因其实现的简便性和效率,在现代编程语言的哈希表实现中更为常见。
拉链法实现固定容量的哈希表
#ifndef HASH_MAP_H
#define HASH_MAP_H
#include <stdint.h> // 包含它是为了使用别名 uint32_t
#include <stdbool.h>
#include <string.h>
#define HASHMAP_CAPACITY 10 // 哈希表中数组的长度固定是 10
// 此时哈希表用于存储字符串类型的键值对
typedef char *KeyType;
typedef char *ValueType;
/**
* @brief 键值对结点
*/
typedef struct node_s {
KeyType key;
ValueType val;
struct node_s *next;
} KeyValueNode;
typedef struct {
// 哈希桶
KeyValueNode *buckets[HASHMAP_CAPACITY]; // 直接给定哈希桶的数量是 10 个
// 哈希函数需要的种子值
uint32_t hash_seed;
} HashMap;
/**
* @brief 创建一个固定容量的哈希表
* @return HashMap * 哈希表
*/
HashMap *hashmap_create();
/**
* @brief 销毁一个哈希表
* @param map 哈希表
*/
void hashmap_destroy(HashMap *map);
/**
* @brief 插入一个键值对
* @param map 哈希表
* @param key 键
* @param val 值
* @return bool 是否插入成功
*/
ValueType hashmap_put(HashMap *map, KeyType key, ValueType val);
/**
* @brief 查询一个键值对
* @param map 哈希表
* @param key 键
* @return
*/
ValueType hashmap_get(HashMap *map, KeyType key);
/**
* @brief 删除一个键值对
* @param map 哈希表
* @param key 键
* @return
*/
bool hashmap_remove(HashMap *map, KeyType key);
#endif // !HASH_MAP_H

固定容量哈希表的创建
创建一个固定容量的哈希表涉及分配内存以存储哈希表结构体,并初始化其成员。
- 分配哈希表结构体内存:使用
calloc为HashMap结构体分配内存。calloc初始化内存为 0 值,确保所有成员被正确初始化。 - 初始化哈希表结构体:为
hash_seed成员设置一个随机值,通常使用当前时间作为种子,以保证哈希函数的随机性。
HashMap *hashmap_create() {
HashMap *map = malloc(sizeof(HashMap));
if (map == NULL) {
printf("错误:malloc 在 hashmap_create 中初始化失败!\n");
exit(1);
}
map->hash_seed = time(NULL);
return map;
}
哈希表的销毁操作
销毁基于拉链法实现的哈希表涉及释放所有链表结点的内存以及哈希表结构体本身的内存。
- 遍历哈希桶:哈希表由一个数组(通常称为哈希桶)组成,每个桶存储了一个链表。
- 释放链表结点:遍历数组中的每个桶,对于每个桶中的链表,逐一释放链表的结点。
- 释放哈希表结构体:在所有链表结点都被释放之后,释放哈希表结构体
map所占用的内存。
void hashmap_destroy(HashMap *map) {
if (map == NULL) return;
// 遍历数组,释放每个桶中的链表结点
for (size_t i = 0; i < HASHMAP_CAPACITY; i++) {
KeyValueNode *curr = map->buckets[i];
while (curr != NULL) {
KeyValueNode *tmp = curr->next;
free(curr->key);
free(curr->value);
free(curr);
curr = tmp;
}
}
// 释放哈希表结构体
free(map);
}
哈希表插入键值对的操作
在哈希表中插入一个键值对涉及以下步骤:
- 计算哈希值:根据给定的键
key计算哈希值,确定键值对应该存储在哪个哈希桶中。 - 检查键是否存在:遍历对应哈希桶中的链表,检查键是否已存在。
- 更新或插入:
- 如果键已存在,更新其对应的值,并返回旧值。
- 如果键不存在,创建新的键值对结点,并将其插入到链表的头部。

ValueType hashmap_put(HashMap *map, KeyType key, ValueType val) {
// 计算 key 的哈希值, 然后判断 key 是否重复
int idx = hash(key, strlen(key), map->hash_seed) % HASHMAP_CAPACITY;
KeyValueNode *curr = map->buckets[idx];
while (curr != NULL) {
if (strcmp(curr->key, key) == 0) {
// key 重复了
ValueType ret = curr->val;
curr->val = val;
return ret;
}
curr = curr->next;
} // while 循环结束时, 若函数仍未返回, 说明 key 不重复, 需要新增一个键值对
// 在 key 不重复的前提下, 分配一个新键值对结点
KeyValueNode *new_node = malloc(sizeof(KeyValueNode));
if (new_node == NULL) {
printf("error: malloc failed in hashmap_put.\n");
exit(-1);
}
new_node->key = key;
new_node->val = val;
// 利用头插法, 把此键值对结点链接到哈希桶中
new_node->next = map->buckets[idx];
map->buckets[idx] = new_node;
return NULL;
}
哈希表查询键值对的操作
在哈希表中查询一个键值对涉及以下步骤:
- 计算哈希值:根据给定的键
key计算哈希值,确定键值对应该存储在哪个哈希桶中。 - 遍历哈希桶:遍历对应哈希桶中的链表,检查键是否存在。
- 返回值:S
- 如果找到键,则返回对应的值。
- 如果键不存在,则返回
NULL或适当的错误值。
ValueType hashmap_get(HashMap *map, KeyType key) {
// 计算 key 的哈希值, 然后找到存储此键值对的哈希桶遍历它
int idx = hash(key, strlen(key), map->hash_seed) % HASHMAP_CAPACITY;
// 遍历哈希桶当中的链表, 找到目标键值对结点
KeyValueNode *curr = map->buckets[idx];
while (curr != NULL) {
if (strcmp(curr->key, key) == 0) {
// 找到目标键值对
return curr->val;
}
curr = curr->next;
}
// while 循环结束时, 函数都没有返回, 说明目标 key 不存在, 查找失败
return NULL;
}
哈希表删除键值对的操作
在哈希表中删除一个键值对涉及以下步骤:
- 计算哈希值:根据给定的键
key计算哈希值,确定键值对应该存储在哪个哈希桶中。 - 初始化指针:初始化两个指针
prev和curr。prev用于指向当前结点的前一个结点,curr用于遍历链表。 - 遍历哈希桶:遍历对应哈希桶中的链表,检查键是否存在。
- 删除结点:如果找到键,则执行删除操作:
- 如果待删除结点是链表的第一个结点(
prev为NULL),更新哈希桶的头指针。 - 否则,将
prev结点的next指针指向curr结点的下一个结点,绕过curr结点。
- 如果待删除结点是链表的第一个结点(
- 释放内存:释放待删除结点的内存。
- 返回结果:
- 如果找到并成功删除键值对,返回
true。 - 如果键不存在,返回
false。
- 如果找到并成功删除键值对,返回
// 删除某个键值对
bool hashmap_remove(HashMap *map, KeyType key) {
// 计算哈希值确定哈希桶的位置
int idx = hash(key, strlen(key), map->hash_seed) % HASHMAP_CAPACITY;
// 初始化两个指针,用于删除结点
KeyValueNode *curr = map->buckets[idx];
KeyValueNode *prev = NULL;
// 遍历链表查找目标 Key
while (curr != NULL) {
// 比较字符串
if (strcmp(key, curr->key) == 0) {
// 已找到目标键值对
if (prev == NULL) {
// 删除的是第一个结点
map->buckets[idx] = curr->next;
}
else
{
// 删除的不是第一个结点
prev->next = curr->next;
}
// free结点
free(curr);
return true; // 删除成功
}
prev = curr; // 更新 prev 为当前节点
curr = curr->next; // 当前结点向后移动
}
// 没找到目标键值对,删除失败
return false;
}
哈希表的动态分析
- 性能影响因素:
- 哈希表操作的性能主要取决于链表的平均长度 L L。
- 链表的基本操作具有 O(L)O(L) 的时间复杂度。
- 链表平均长度的影响因素:链表的平均长度受哈希冲突频率的影响。哈希冲突越多,链表越长。
- 性能优化方向:
- 设计更好的哈希函数以减少冲突,从而降低链表的平均长度。
- 增加哈希桶的数量,即增加底层数组的长度,以减少每个桶中的元素数量。
- 性能极端情况:
- 在最坏情况下,如果大量元素被挂起,哈希表的操作性能接近链表,即 O(L)O(L)。
- 在最佳情况下,链表很短,操作性能接近数组的随机访问,即 O(1)O(1)。
- 负载因子:
- 负载因子是衡量哈希表“装满”程度的指标,定义为键值对总数与底层数组长度的比值,即 负载因子=\dfrac{哈希表中的键值对总数}{哈希表底层数组的长度}
- 负载因子越小,挂起的节点越少,性能越好。
- 平衡点:负载因子过低会浪费空间,需要找到一个平衡点。
- 健康状态:一般来说,负载因子在 0.7 到 0.75 以下时,哈希表处于健康状态,性能优秀。
- 扩容操作:当负载因子超过阈值时,意味着需要进行扩容操作,以维持性能。
- 动态哈希表:实现基于动态数组的动态哈希表,以适应不断变化的数据量。
动态哈希表的实现

动态哈希表的核心操作:
- 新增操作:
- 首先计算键(key)的哈希值,以确定哈希桶的位置。
- 遍历哈希桶中的单链表,检查键是否存在。如果键已存在,则更新其对应的值(value),并结束函数。
- 删除和查询操作:
- 删除和查询操作在处理上没有区别。它们都需要遍历哈希桶中的链表,找到对应的键,然后执行相应的操作。
- 新增操作的特殊情况:
- 如果键不存在,需要执行新增结点的操作。
- 计算负载因子,以确定是否需要进行扩容。通常设定一个负载因子的阈值,如 0.7 或 0.75。
- 扩容操作:
- 如果负载因子超过阈值,执行扩容操作,以保持哈希表的性能。
- 扩容完成后,可能需要重新计算哈希值和哈希桶的位置,因为数组的长度已经改变。
- 插入新结点:
- 如果不需要扩容,或者扩容已经完成,分配并初始化一个新的结点。
- 使用链表的头插法将新结点链接到哈希桶中,完成插入操作。
- 细节处理:
- 如果没有执行扩容,可以直接利用最初计算的哈希值和索引来新增结点。
- 如果进行了扩容,由于数组长度的增加,需要重新计算哈希值和哈希桶的位置。
动态哈希表的核心操作
- 新增操作:
- 首先计算键(key)的哈希值,以确定哈希桶的位置。
- 遍历哈希桶中的单链表,检查键是否存在。如果键已存在,则更新其对应的值(value),并结束函数。
- 删除和查询操作:
- 删除和查询操作在处理上没有区别。它们都需要遍历哈希桶中的链表,找到对应的键,然后执行相应的操作。
- 新增操作的特殊情况:
- 如果键不存在,需要执行新增结点的操作。
- 计算负载因子,以确定是否需要进行扩容。通常设定一个负载因子的阈值,如 0.7 或 0.75。
- 扩容操作:
- 如果负载因子超过阈值,执行扩容操作,以保持哈希表的性能。
- 扩容完成后,可能需要重新计算哈希值和哈希桶的位置,因为数组的长度已经改变。
- 插入新结点:
- 如果不需要扩容,或者扩容已经完成,分配并初始化一个新的结点。
- 使用链表的头插法将新结点链接到哈希桶中,完成插入操作。
- 细节处理:
- 如果没有执行扩容,可以直接利用最初计算的哈希值和索引来新增结点。
- 如果进行了扩容,由于数组长度的增加,需要重新计算哈希值和哈希桶的位置。
动态哈希表的扩容操作实现
- 扩容策略选择:选择一个合适的扩容策略,例如,可以将哈希表的大小加倍。
- 核心逻辑:在扩容过程中,需要对每个键值对结点重新计算哈希值,可能还会更新种子值以增加随机性。
- 再哈希过程:每个键值对结点都需要根据新的数组长度重新计算其存储位置,并挂载到相应的链表中。
- 性能考虑:再哈希过程复杂且性能消耗大,因此扩容操作应谨慎执行。
- Java 中的实现:Java 的哈希表实现在负载因子过大时,会将链表转换为红黑树,以提升性能。
- 具体实现过程:
- 使用
malloc重新分配一块更大的内存空间。 - 遍历老的动态数组,将所有结点重新挂载到新的动态数组中。
- 使用
- 避免使用
realloc:避免使用realloc,因为它可能会移动内存块,导致现有指针失效。 - 扩容后的哈希表可用性:扩容后的哈希表应保持可用,不影响其功能和性能。


扩容过程的实现思路的总结:
- 确定新数组长度:根据扩容策略,计算出新动态数组所需的长度,通常这会是原始长度的两倍。
- 分配新数组:使用
malloc分配一个新的、更长的动态数组。随着哈希桶数量的增加,可以考虑更新种子值以提高哈希表的随机性。 - 核心操作 – 再哈希:遍历原始动态数组中的每个键值对结点,重新计算它们的哈希值,并根据新的数组长度进行取模运算,以确定它们在新数组中的位置。然后将这些结点链接到新的动态数组对应的哈希桶中。
- 释放旧数组:在确保所有结点都已迁移到新数组之后,释放旧动态数组的内存。重要的是不要释放结点本身,因为它们仍然需要保留在新的哈希表中。
- 更新哈希表参数:更新哈希表的核心参数,包括哈希桶数组、容量以及可能的种子值等。
#ifndef DYNAMIC_HASHMAP_H
#define DYNAMIC_HASHMAP_H
#include <stdbool.h>
typedef char *KeyType;
typedef char *ValueType;
#include <stdint.h>
typedef struct node_s {
KeyType key;
ValueType val;
struct node_s *next;
} KeyValueNode;
typedef struct {
KeyValueNode **buckets; ///< 此时哈希桶是一个动态数组,指向 char* 元素的指针,所以是一个二级指针
int size; ///< 键值对的个数
int capacity; ///< 数组的长度
uint32_t hash_seed; ///< 哈希函数需要的种子值
} DynamicHashMap;
/**
* @brief 创建一个固定容量的哈希表
* @return DynamicHashMap* 哈希表
*/
DynamicHashMap *hashmap_create();
/**
* @brief 销毁一个哈希表
* @param map 哈希表
*/
void hashmap_destroy(DynamicHashMap *map);
/**
* @brief 插入一个键值对
* @param map 哈希表
* @param key 键
* @param val 值
* @return ValueType 插入的值
*/
ValueType hashmap_put(DynamicHashMap *map, KeyType key, ValueType val);
/**
* @brief 查询一个键值对
* @param map 哈希表
* @param key 键
* @return ValueType 值
*/
ValueType hashmap_get(DynamicHashMap *map, KeyType key);
/**
* @brief 删除一个键值对
* @param map 哈希表
* @param key 键
* @return bool
*/
bool hashmap_remove(DynamicHashMap *map, KeyType key);
#endif // !DYNAMIC_HASHMAP_H
动态数组哈希表的创建和销毁操
- 创建哈希表:
- 分配内存以存储哈希表结构体
DynamicHashMap。 - 分配内存以存储哈希桶数组
buckets,每个桶是一个指向KeyValueNode的指针。
- 分配内存以存储哈希表结构体
- 初始化哈希表:
- 使用
calloc初始化哈希桶数组,确保所有桶初始为空。 - 设置哈希表的初始容量、大小和哈希种子。
- 使用
- 销毁哈希表:
- 遍历哈希桶数组,释放每个桶中的链表结点。
- 释放哈希桶数组。
- 释放哈希表结构体。
#include "dynamic_hashmap.h"
#define DEFAULT_CAPACITY 8 // 哈希表的初始默认容量是8
// 创建一个固定容量的哈希表
DynamicHashMap *hashmap_create() {
DynamicHashMap *map = malloc(sizeof(DynamicHashMap));
if (map == NULL) {
printf("Error: malloc failed in hashmap_create\n");
exit(1);
}
map->buckets = calloc(DEFAULT_CAPACITY, sizeof(KeyValueNode *));
if (map->buckets == NULL) {
// 不要忘记先free结构体
free(map);
printf("Error: calloc failed in hashmap_create\n");
exit(1);
}
// 初始化其它成员
map->size = 0;
map->capacity = DEFAULT_CAPACITY;
map->hash_seed = time(NULL);
return map;
}
// 销毁一个哈希表
void hashmap_destroy(DynamicHashMap *map) {
// 1.先遍历动态数组销毁链表的每一个结点
for (int i = 0; i < map->capacity; i++) {
KeyValueNode *curr = map->buckets[i];
while (curr != NULL) {
KeyValueNode *tmp = curr->next;
free(curr);
curr = tmp;
}
}
// 2.再销毁动态数组
free(map->buckets);
// 3.最后销毁哈希表结构体
free(map);
}
动态哈希表的插入操作
- 计算哈希值:根据键
key计算哈希值,确定键值对应该存储在哪个哈希桶中。 - 检查键是否存在:遍历对应哈希桶中的链表,检查键是否存在。
- 更新或插入:
- 如果键已存在,更新其对应的值,并返回旧值。
- 如果键不存在,创建新的键值对结点,并将其插入到链表的头部。
- 负载因子检查:在插入新键值对之前,检查当前哈希表的负载因子。如果负载因子达到阈值,执行扩容操作。
- 扩容操作:
- 使用
calloc创建一个新的、更大容量的动态数组。 - 重新哈希所有现有键值对,将它们映射到新的哈希桶中。
- 使用
- 使用
calloc而非realloc:在扩容时,使用calloc而不是realloc,因为calloc会初始化新分配的内存为 0,这有助于简化重新哈希的过程。
#define LOAD_FACTOR_THRESHOLD 0.75 // 负载因子的阈值
#define CAPACITY_THRESHOLE 1024 // 数组容量的阈值
/* murmur_hash2 */
static uint32_t hash(const void* key, int len, uint32_t seed) {
const uint32_t m = 0x5bd1e995;
const int r = 24;
uint32_t h = seed ^ len;
const unsigned char* data = (const unsigned char*)key;
while (len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
switch (len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0];
h *= m;
};
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return h;
}
static void rehash(KeyValueNode *curr, KeyValueNode **new_table, int new_capacity, uint32_t seed) {
// 计算 key 的哈希值
int len = strlen(curr->key);
int idx = hash(curr->key, len, seed) % new_capacity;
// 头插法
curr->next = new_table[idx];
new_table[idx] = curr;
}
// 对哈希表进行扩容操作
static void grow_capacity(DynamicHashMap *map) {
/*
* 扩容策略:
* 1. 如果容量没有达到阈值,那就每次将长度扩大为原先的 2 倍
* 2. 如果容量达到阈值,此时哈希表已经很长了,为了避免扩容过程性能损耗过大
* 所以扩容保守一些,每次只扩容阈值长度的容量
*
* 扩容的过程:
* 1. 每个键值对结点都要重新计算哈希值,重新映射到新哈希桶中(新数组)
* 2. 原先的动态数组的链表很复杂,难以进行重哈希操作,建议直接丢弃它
* 重新创建一个新动态数组
*/
int new_capacity =
(map->capacity <= CAPACITY_THRESHOLE) ?
(map->capacity << 1) :
(map->capacity + CAPACITY_THRESHOLE);
// 动态数组扩容需要使用 calloc
KeyValueNode **new_buckets = calloc(new_capacity, sizeof(KeyValueNode *));
if (new_buckets == NULL) {
printf("Error: calloc failed in grow_capacity\n");
exit(1);
}
// 每次扩容都更改一次哈希种子,提高安全性
uint32_t seed = time(NULL);
// 将所有键值对重新映射到新数组中
for (int i = 0; i < map->capacity; i++) {
KeyValueNode *curr = map->buckets[i];
while (curr != NULL) {
KeyValueNode *next = curr->next;
// 重新进行哈希映射
rehash(curr, new_buckets, new_capacity, seed);
curr = next;
}
}
// 将旧动态数组free,但是注意不要free键值对结点,结点已经被链接到新数组中了。
free(map->buckets);
// 更新 HashMap 的信息
map->buckets = new_buckets;
map->capacity = new_capacity;
map->hash_seed = seed;
}
// 插入一个键值对
// 1. 如果 key 不存在,则添加键值对结点
// 2. 如果 key 存在,则更新 val,将旧的 val 返回
ValueType hashmap_put(DynamicHashMap *map, KeyType key, ValueType val) {
// 计算 key 的哈希值确定存储位置
int idx = hash(key, strlen(key), map->hash_seed) % (map->capacity);
// 遍历链表
KeyValueNode *curr = map->buckets[idx];
while (curr != NULL) {
if (strcmp(key, curr->key) == 0) {
// 更新 key 关联的 val, 并将旧的 value 返回
ValueType old_val = curr->val;
curr->val = val;
return old_val;
}
curr = curr->next;
} // while 循环结束时, curr 是一个 NULL
// 键值对不存在,即需要将键值对插入
// 插入操作前需要计算当前哈希表的负载因子
double load_factor = (1.0 * map->size) / (map->capacity);
if (load_factor >= LOAD_FACTOR_THRESHOLD) {
// 当前哈希表负载因子已达到阈值,将动态数组进行扩容
grow_capacity(map);
// 数组长度已变,需要再哈希确定当前键值对的存储位置
idx = hash(key, strlen(key), map->hash_seed) % (map->capacity);
}
// 开始插入新键值对
KeyValueNode *new_node = malloc(sizeof(KeyValueNode));
if (new_node == NULL) {
printf("Error: malloc failed in hashmap_put\n");
exit(1);
}
// 初始化结点
new_node->key = key;
new_node->val = val;
// 链表的头插法
new_node->next = map->buckets[idx];
map->buckets[idx] = new_node;
// 不要忘记更新size
map->size++;
return NULL;
}
动态哈希表的访问和删除操作
- 访问键值对:
- 通过计算键
key的哈希值,确定其在哈希表中的存储位置。 - 遍历对应哈希桶的链表,查找与给定键匹配的结点。
- 通过计算键
- 删除键值对:
- 同样,首先计算键的哈希值,找到对应的哈希桶。
- 使用两个指针
prev和curr遍历链表,找到要删除的结点。 - 删除结点,并更新前驱结点的
next指针。
// 查询一个键值对
ValueType hashmap_get(DynamicHashMap *map, KeyType key) {
// 计算key的哈希值,从而确定哈希桶
int idx = hash(key, strlen(key), map->hash_seed) % map->capacity;
// 遍历哈希桶的链表,判断 key 是否存在
KeyValueNode *curr = map->buckets[idx];
while (curr != NULL) {
if (strcmp(key, curr->key) == 0) {
// 找到目标键值对
return curr->val;
}
curr = curr->next;
} // curr == NULL
// 没找到目标键值对
return NULL;
}
// 删除某个键值对
bool hashmap_remove(DynamicHashMap *map, KeyType key) {
// 计算key的哈希值,从而确定哈希桶
int idx = hash(key, strlen(key), map->hash_seed) % map->capacity;
// 初始化两个指针,一个指向链表当前结点,一个指向当前结点的前驱
KeyValueNode *prev = NULL;
KeyValueNode *curr = map->buckets[idx];
while (curr != NULL) {
if (strcmp(key, curr->key) == 0) {
// 找到了要删除的节点
if (prev == NULL) {
// 删除的是哈希桶的第一个节点,于是更新头指针
map->buckets[idx] = curr->next;
}
else {
// 删除的是哈希桶中的非第一个节点,只需要让当前结点的前驱结点指向当前结点的后继
prev->next = curr->next;
}
free(curr);
map->size--;
return true;
}
// 继续遍历链表
prev = curr;
curr = curr->next;
}
// 没找到指定key的节点
return false;
}
哈希表的应用
哈希表作为一种高效的数据结构,在软件开发和算法设计中扮演着重要角色。
- 作为容器存储键值对:哈希表能够存储键值对,这使得它成为处理如“用户名-密码”等关联数据的理想选择。高级编程语言通常提供哈希表的库实现,例如:
- C++中的
unordered_map和unordered_set,它们提供了快速的插入、查询和删除操作。 - Java 中的
HashMap、HashSet和Hashtable,这些集合容器基于哈希表实现,用于存储键值对或唯一元素。
- C++中的
- 算法领域的应用:
- 查找重复或唯一元素:哈希表的快速查询特性使其在查找重复项或确保元素唯一性方面非常有用。
- 计数器:哈希表可用于统计元素出现的次数,适用于频率统计等场景。
- 数据库索引:哈希表可以作为数据库索引,提高数据检索的速度。
- 缓存实现:利用哈希表的快速查询能力,实现高效的缓存机制,如 Redis 这样的内存数据库,它广泛使用哈希表来存储和管理键值对数据。